انقلاب در نظارت بر سلامت با دادههای پوشیدنی
دستگاههای پوشیدنی با فراهم آوردن دادههای فیزیولوژیکی و رفتاری چندوجهی و پیوسته – از سیگنالهای قلبی و الگوهای خواب گرفته تا سطح فعالیت و شاخصهای استرس – نظارت بر سلامت را متحول کردهاند. به دلیل پیشرفت در فناوری حسگرها، ضبط حجم زیادی از دادهها به طور فزایندهای امکانپذیر شده است، اما هزینه برچسبگذاری همچنان بالا است و نیاز به حاشیهنویسیهای بلادرنگ کاربر یا مطالعات بالینی پرزحمت دارد. یادگیری خود-نظارتشده (SSL) با استفاده مستقیم از دادههای بدون برچسب برای یادگیری ساختارهای زیربنایی، مانند روابط فیزیولوژیکی ظریف، این محدودیت را برطرف میکند. هنگامی که SSL در مقیاس بزرگ به کار گرفته میشود، میتواند امکان ایجاد مدلهای بنیادی را فراهم کند که نمایشهای غنی و قابل تعمیم را برای طیف گستردهای از وظایف سلامتی پاییندست تولید میکنند.
با این حال، هنگام به کارگیری SSL در حوزه پوشیدنیها، یک محدودیت بحرانی وجود دارد: روشهای پیشرفته SSL فرض میکنند که دادهها کامل و بدون وقفه هستند – امری که در جریانهای حسگر پوشیدنی در دنیای واقعی، که شکافها به ناچار به دلیل برداشتن دستگاه، شارژ، شل شدن متناوب، آرتیفکتهای حرکتی، حالتهای صرفهجویی در باتری، یا نویز محیطی رخ میدهند و ما آن را “ناقص بودن” مینامیم، نادر است. در واقع، ما متوجه شدیم که هیچ نمونهای از میان 1.6 میلیون پنجره یکروزه ما، 0% ناقصی نداشته است. از لحاظ تاریخی، چالش دادههای تکه تکه شده محققان را مجبور کرده است که به روشهای تکمیل داده برای پر کردن بخشهای از دست رفته، یا فیلتر کردن تهاجمی برای حذف نمونههای دارای داده ناقص، تکیه کنند. هیچ یک از این روشها راه حل بهینهای نیستند، زیرا اولی ممکن است سوگیریهای ناخواسته را معرفی کند، در حالی که دومی دادههای ارزشمند را از بین میبرد.
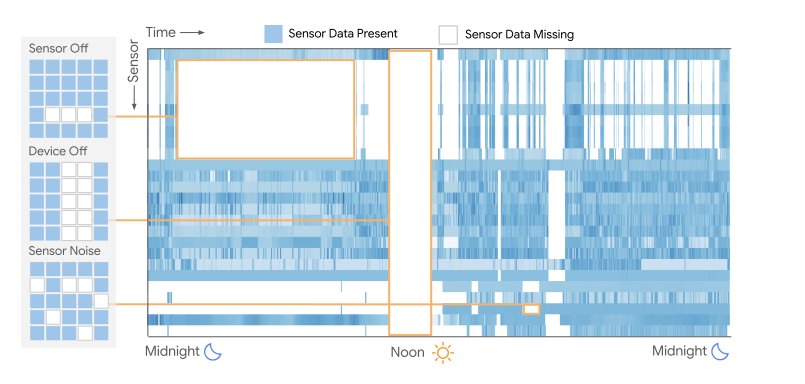
دادههای از دست رفته در ضبطهای حسگر پوشیدنی فراگیر هستند. حالتهای رایج نقص در نمونه یکروزه از دادههای حسگر پوشیدنی چندوجهی در بالا مشخص شدهاند. ما اشاره میکنیم که هیچ نمونهای از میان 1.6 میلیون پنجره یکروزه ما 0% نقص نداشته است.
معرفی LSM-2: رویکردی نوین برای دادههای ناقص
در مقاله “LSM-2: یادگیری از دادههای حسگر پوشیدنی ناقص“، ما Adaptive and Inherited Masking (AIM) را ارائه میکنیم، یک چارچوب آموزشی SSL جدید که مستقیماً از دادههای ناقص یاد میگیرد. AIM به جای اینکه شکافهای داده را به عنوان اندازهگیریهای نادرست که باید پر شوند، در نظر بگیرد، مستقیماً از ضبطهای ناقص با در نظر گرفتن نقص به عنوان یک مصنوع طبیعی از دادههای دنیای واقعی یاد میگیرد. با استفاده از AIM، ما یک مدل حسگر بزرگ (LSM-2) را توسعه میدهیم که مدل بنیادی قبلی ما برای دادههای حسگر پوشیدنی (LSM-1، ارائه شده در ICLR ‘25) را بهبود میبخشد. ما نشان میدهیم که LSM-2 عملکرد قویای را حتی زمانی که حسگرها خراب میشوند یا پنجرههای زمانی حذف میشوند، به دست میآورد و تخریب قابل توجهی کمتر از مدلهای آموزشدیده بر روی دادههای تکمیل شده از خود نشان میدهد.
این مدل پیشرفته نه تنها کارایی بالاتری در پردازش دادههای ناقص دارد، بلکه به طور چشمگیری پایداری خود را در برابر شرایط واقعی و غیرایدهآل دادهبرداری از حسگرهای پوشیدنی اثبات میکند. این رویکرد نوآورانه، مسیر را برای کاربردهای گستردهتر هوش مصنوعی در زمینه سلامت هموار میکند و به دستگاههای پوشیدنی اجازه میدهد تا در شرایط چالشبرانگیز نیز اطلاعات دقیق و قابل اعتمادی را ارائه دهند.
تمرکز AIM بر یادگیری مستقیم از دادههای ناقص، یک تغییر پارادایم اساسی در پردازش سیگنالهای حسگر پوشیدنی است. این بدان معناست که دیگر نیازی به تکیه بر روشهای پرهزینه و بالقوه سوگیرانه برای “تمیز کردن” دادهها قبل از آموزش مدل نیست. در عوض، مدل به گونهای طراحی شده است که ذاتاً نقص و پراکندگی را به عنوان بخشی طبیعی از ورودی درک کند و از آن بیاموزد، که به نتایج قویتر و قابل اعتمادتر منجر میشود.
AIM با ماسکگذاری تطبیقی و موروثی
در قلب نوآوری AIM، رویکرد منحصربهفرد آن برای مدیریت شکافهای اجتنابناپذیر در دادههای حسگر دنیای واقعی قرار دارد. برخلاف روشهای سنتی SSL که دادههای ناقص را دور میاندازند یا تلاش میکنند مقادیر از دست رفته را پر کنند، AIM این شکافها را به عنوان ویژگیهای طبیعی دادههای پوشیدنی در آغوش میگیرد. AIM به عنوان یک توسعه از چارچوب پیشآموزش خودرمزگذار ماسکشده (MAE)، با بازسازی نمونههای ورودی ماسکشده، ساختار زیربنایی دادههای حسگر را یاد میگیرد. این رویکرد به مدل اجازه میدهد تا روابط پیچیده در دادهها را حتی در حضور اطلاعات از دست رفته، درک کند.
با این حال، در حالی که روشهای سنتی MAE به نسبت ماسکگذاری ثابتی برای حذف کارآمد توکنهای ماسکشده (یعنی تعداد ثابتی از توکنهای ماسکشده از طریق رمزگذار عبور نمیکنند و در نتیجه پیچیدگی محاسباتی کاهش مییابد) متکی هستند، تکهتکه شدن دادههای حسگر غیرقابل پیشبینی است و منجر به تعداد متغیری از توکنهای ماسکشده میشود. AIM با جفت کردن حذف توکن با ماسکگذاری توجه، این چالش اساسی دادههای پوشیدنی را برطرف میکند. در طول پیشآموزش، مجموعه توکنهایی که باید ماسک شوند، شامل مواردی است که از دادههای حسگر پوشیدنی به ارث رسیده و در آن ذاتی هستند، به علاوه مواردی که عمداً برای هدف آموزشی بازسازی ماسک شدهاند. این ترکیب هوشمندانه، مدل را قادر میسازد تا هم با نقصهای طبیعی و هم با نقصهای مصنوعی به طور همزمان مقابله کند.
AIM ابتدا حذف را به تعداد ثابتی از توکنهای ماسکشده اعمال میکند و کارایی محاسباتی پیشآموزش را با کاهش طول دنباله پردازش شده توسط رمزگذار بهبود میبخشد. سپس AIM هر توکن ماسکشده باقیمانده – چه به طور طبیعی از دست رفته باشد و چه بخشی از وظیفه بازسازی – را به صورت تطبیقی از طریق ماسکگذاری توجه در بلوک ترنسفورمر رمزگذار مدیریت میکند. در طول تنظیم دقیق و ارزیابی وظایف تمایزدهنده، که در آن توکنهای ماسکشده صرفاً شامل شکافهای دادهای طبیعی هستند، AIM از ماسکگذاری توجه برای تمام توکنهای ماسکشده استفاده میکند. از طریق این رویکرد ماسکگذاری دوگانه، و با در نظر گرفتن توکنهای طبیعی و مصنوعی ماسکشده به عنوان معادل، AIM به مدل آموزش میدهد که با تکهتکه شدن متغیر ذاتی حسگرهای پوشیدنی کار کند. این توانایی تطبیق، LSM-2 را به ابزاری بینظیر برای کاربردهای عملی تبدیل میکند.

پیشآموزش (A) و ارزیابی (B) AIM برای LSM-2. در طول پیشآموزش، AIM از ماسک مصنوعی برای یادگیری بازسازی و از ماسک موروثی برای مدلسازی نقصهای دنیای واقعی استفاده میکند. سپس، در طول ارزیابی، میتوانیم از جاسازی آگاه از نقص برای پیشبینی اهداف سلامتی، مانند فشار خون بالا، مستقیماً از دادههای حسگر ذاتاً تکه تکه شده استفاده کنیم.
آموزش و ارزیابی مدل
ما از مجموعه دادهای با 40 میلیون ساعت داده پوشیدنی که از بیش از 60,000 شرکتکننده در دوره مارس تا مه 2024 نمونهبرداری شدهاند، استفاده میکنیم. این مجموعه داده به طور کامل ناشناس یا غیرقابل شناسایی شد تا اطمینان حاصل شود که اطلاعات شرکتکنندگان حذف شده و حریم خصوصی حفظ میشود. افراد از انواع ساعتها و ردیابهای هوشمند Fitbit و Google Pixel استفاده میکردند و رضایت خود را برای استفاده از دادههایشان برای تحقیق و توسعه محصولات و خدمات جدید سلامتی و تندرستی اعلام کردند. از افراد خواسته شد تا جنسیت، سن و وزن خود را به صورت خودگزارشی ارائه دهند. این حجم عظیم از دادهها، زمینه لازم برای آموزش یک مدل قدرتمند و تعمیمپذیر را فراهم آورد.
برای پیشآموزش LSM-2، ما از تکنیک SSL AIM معرفی شده در بخش قبلی استفاده میکنیم. AIM یک هدف آموزشی بازسازی ماسکشده را پیادهسازی میکند و یاد میگیرد که دادههای به طور طبیعی از دست رفته را درک کند و دادههای به طور مصنوعی ماسکشده را تکمیل کند. این چارچوب یکپارچه به LSM-2 اجازه میدهد تا ساختار زیربنایی (از جمله نقص) ذاتی در دادههای حسگر پوشیدنی را یاد بگیرد. این روش آموزش باعث میشود که مدل به جای نادیده گرفتن نواقص، آنها را به عنوان بخشی از واقعیت دادهها در نظر بگیرد و از این طریق قابلیتهای یادگیری خود را بهبود بخشد.
ما مجموعهای از وظایف پاییندستی را برای ارزیابی مدل پیشآموزششده، با استفاده از ابردادههایی که در کنار سیگنالهای حسگر برای اهداف تحقیق و توسعه جمعآوری شده بودند، تنظیم میکنیم. این وظایف شامل فعالیتهای حاشیهنویسیشده توسط کاربر از مجموعهای از 20 دسته مختلف (مانند دویدن، اسکی، قایقرانی و بازی گلف) و تشخیصهای خودگزارشی فشار خون بالا و اضطراب است. این دادهها به مجموعههای تنظیم دقیق و ارزیابی تقسیم شدند که در آن دادههای هر فرد فقط در مجموعه تنظیم یا ارزیابی بود و نه هر دو. دادههای افراد استفاده شده در مرحله پیشآموزش نیز در مراحل تنظیم دقیق یا ارزیابی گنجانده نشدند.
قابلیتهای مولد LSM-2 از طریق وظایف تکمیل تصادفی، درونیابی زمانی، برونیابی زمانی (پیشبینی)، و تکمیل حسگر، که در کار LSM-1 ما توضیح داده شدهاند، ارزیابی میشوند. سودمندی جاسازیهای LSM-2 از طریق پروب خطی در تعدادی از وظایف تمایزدهنده ارزیابی میشود. به طور خاص، ما قابلیت کاربرد جاسازیهای LSM-2 را برای وظایف طبقهبندی باینری فشار خون بالا، طبقهبندی باینری اضطراب، و تشخیص فعالیت 20 کلاسه اندازهگیری میکنیم. ما توانایی LSM-2 را در مدلسازی فیزیولوژی از طریق وظایف رگرسیون سن و BMI ارزیابی میکنیم.
نتایج کلیدی و پیشرفتهای LSM-2
مدل LSM-2 مبتنی بر AIM تطبیقپذیری قابل توجهی را نشان میدهد و از مدل قبلی خود، LSM-1، در سه حوزه کلیدی پیشی میگیرد: طبقهبندی شرایط و فعالیتهای سلامتی (مانند فشار خون بالا، اضطراب، و تشخیص فعالیت 20 کلاسه)، بازسازی دادههای از دست رفته (مانند بازیابی سیگنالهای حسگر از دست رفته)، و پیشبینی معیارهای سلامت پیوسته (مانند BMI با همبستگی بهبود یافته). مقایسههای اضافی با خطوط پایه نظارتشده و پیشآموزشدیده را میتوانید در مقاله ما بیابید. این نتایج نشان میدهد که AIM یک جهش مهم در پردازش دادههای ناقص به ارمغان آورده است.
عملکرد برتر LSM-2 در این زمینهها حاکی از توانایی آن در استخراج الگوهای معنادار حتی از مجموعههای دادهای است که به طور ذاتی ناقص و ناهمگون هستند. این ویژگی برای کاربردهای بالینی و تحقیقاتی که دادههای حسگر پوشیدنی اغلب در شرایط غیرکنترلشده جمعآوری میشوند و ممکن است حاوی شکافها یا نویز باشند، بسیار حیاتی است. این مدل میتواند به پزشکان و محققان کمک کند تا بینشهای دقیقتری را از دادههای بیماران به دست آورند و تصمیمگیریهای بهتری داشته باشند.
علاوه بر این، توانایی LSM-2 در بازسازی دقیق دادههای از دست رفته، ارزش آن را به عنوان یک ابزار تشخیصی و نظارتی افزایش میدهد. این بدان معناست که حتی در صورت قطعی یا نقص موقتی حسگر، مدل میتواند اطلاعات از دست رفته را با دقت قابل قبولی تخمین بزند و یک دید جامع از وضعیت سلامتی فرد را حفظ کند. این قابلیت، اطمینانپذیری سیستمهای پایش سلامت مبتنی بر هوش مصنوعی را به طور چشمگیری بهبود میبخشد و پتانسیل کاربردهای آن را در سناریوهای زندگی واقعی گسترش میدهد.
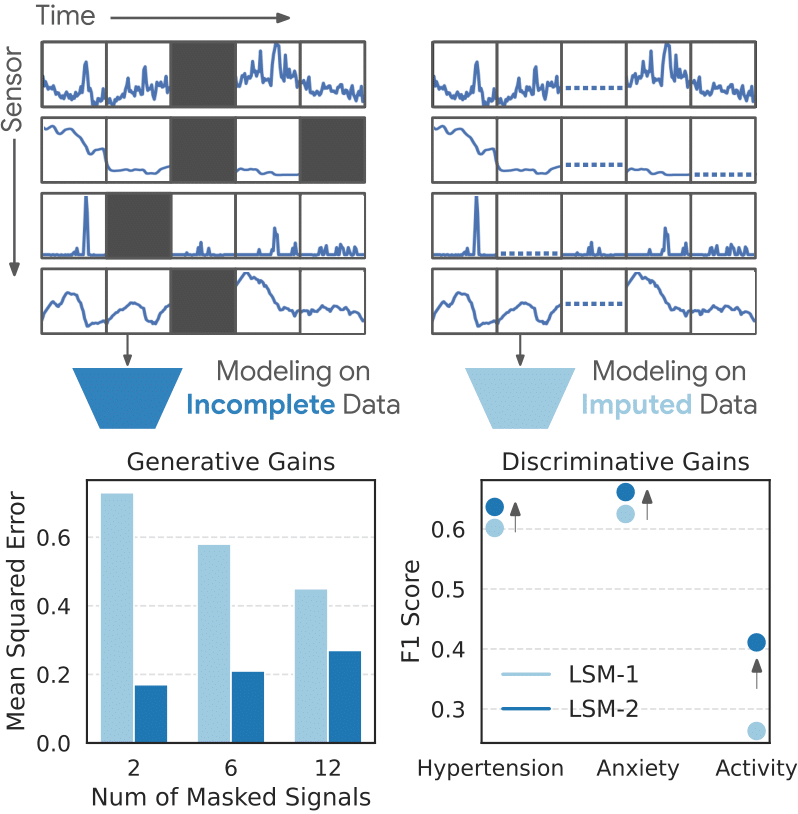
LSM-2 نقصهای دنیای واقعی را بدون تکمیل داده مدلسازی میکند و به آن امکان میدهد خطای بازسازی کمتری (چپ) و امتیازات طبقهبندی بالاتری (راست) را در مقایسه با LSM-1 به دست آورد.
پایداری در برابر دادههای ناقص و مقیاسپذیری
LSM-2 در سناریوهای واقعبینانهای که حسگرها خراب میشوند یا دادهها ناقص هستند، برتری مییابد. شکل زیر وضعیتهایی را شبیهسازی میکند که در آن تمام فیدهای حسگر یا دادههای مربوط به کل بخشهایی از روز ممکن است از دست رفته باشند. این امر واقعیت را بازتاب میدهد که دستگاههای پوشیدنی مختلف ممکن است دارای مجموعههای حسگر متفاوتی باشند، یا اینکه یک فرد ممکن است دستگاه خود را تنها برای بخشهایی از روز استفاده کند. در اینجا ما دریافتیم که LSM-2 مبتنی بر AIM در مقایسه با LSM-1 در برابر این حذفها مقاومتر عمل میکند. این پایداری به مدل اجازه میدهد تا در محیطهای کاربری پیچیده و متغیر، عملکرد خود را حفظ کند.
قابلیت LSM-2 برای مدیریت موثر دادههای ناقص و جزئی، آن را از نسلهای قبلی مدلها متمایز میکند. در گذشته، این چالشها اغلب منجر به از دست دادن دادههای ارزشمند یا نیاز به روشهای پرهزینه برای بازیابی اطلاعات میشد. اما با رویکرد AIM، LSM-2 میتواند از اطلاعات موجود نهایت استفاده را ببرد و حتی در غیاب دادههای کامل نیز بینشهای دقیقی ارائه دهد. این امر به ویژه برای کاربردهای طولانیمدت پایش سلامت، که در آن جمعآوری دادههای بیوقفه اغلب غیرممکن است، اهمیت دارد.
علاوه بر پایداری، LSM-2 بهبود مقیاسپذیری را در بین کاربران، حجم داده، محاسبات و اندازه مدل در مقایسه با LSM-1 نشان میدهد. در حالی که مدل قبلی نشانههایی از فلاتگیری را نشان میدهد، LSM-2 با دادههای بیشتر همچنان بهبود مییابد و هنوز به اشباع نرسیده است. این ویژگی به این معنی است که LSM-2 پتانسیل رشد و بهبود مداوم را با افزایش حجم دادهها و منابع محاسباتی دارد، که آن را به یک راهحل آیندهنگر برای تحقیقات و توسعه در حوزه سلامت پوشیدنی تبدیل میکند.
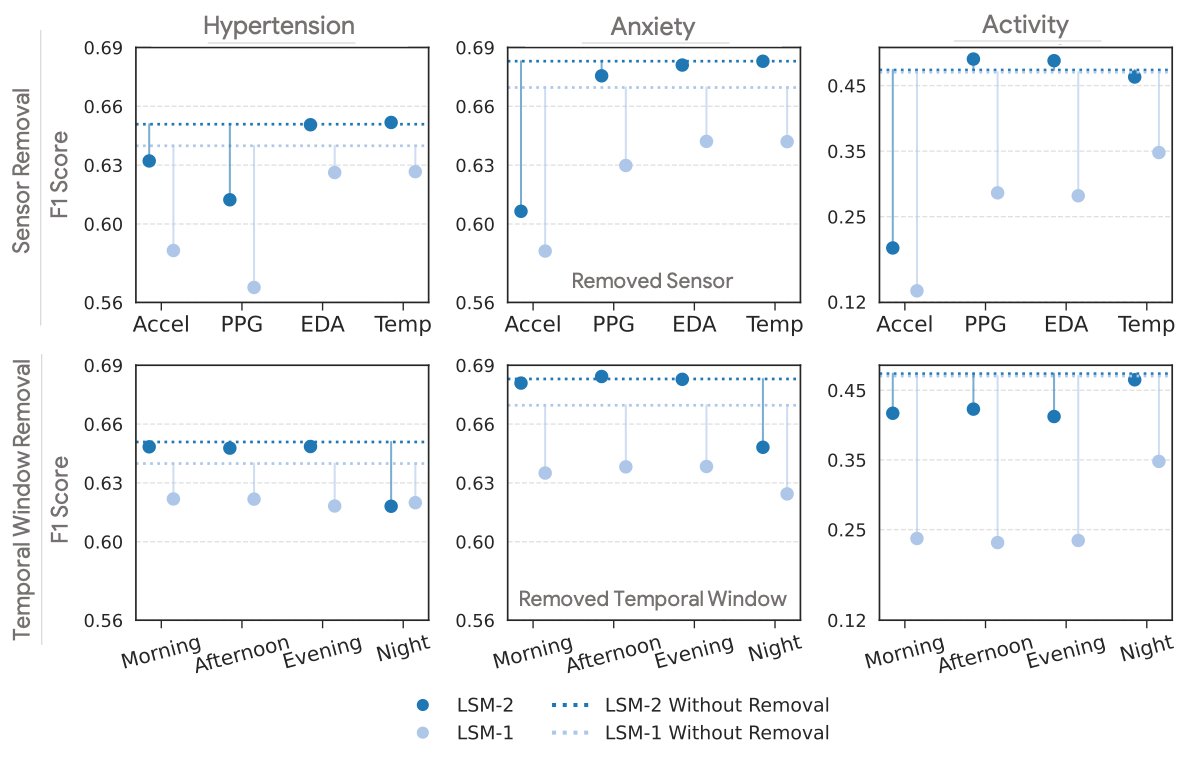
LSM-2 در برابر دادههای از دست رفته مقاومتر از LSM-1 است و کمتر از عملکرد اصلی خود (خط نقطهچین) نسبت به مدل قبلی خود، هنگامی که تمام فیدهای حسگر یا دورههایی از روز حذف میشوند، تخریب میشود.
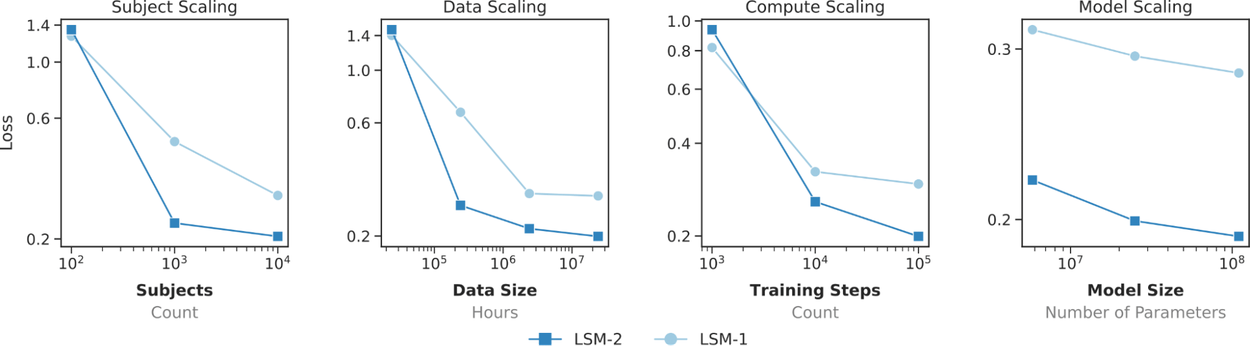
LSM-2 مقیاسپذیری بهبود یافتهای را نسبت به LSM-1 در بین سوژهها، دادهها، محاسبات و اندازه مدل نشان میدهد.
نتیجهگیری: آینده هوش مصنوعی پوشیدنی
مدل بنیادی LSM-2، که با AIM پیشآموزش دیده است، نشاندهنده پیشرفت در جهت فناوری سلامت پوشیدنی مفیدتر و قابل استفادهتر است. اساساً، AIM به LSM-2 آموزش میدهد که شکافهای طبیعی در جریانهای حسگر دنیای واقعی را درک و از آنها بهرهبرداری کند تا بینشهای قابل اعتمادی از دادههای ناقص به دست آورد. این نوآوری به این معنی است که هوش مصنوعی پوشیدنی سرانجام میتواند واقعیت نامرتب دادههای حسگر را بپذیرد، یکپارچگی دادهها را حفظ کند، و در عین حال از تمام اطلاعات موجود استفاده کند.
این رویکرد نه تنها بار پردازش دادههای اولیه را کاهش میدهد، بلکه قابلیت اعتماد و دقت نتایج را نیز در کاربردهای عملی افزایش میدهد. با قابلیت تطبیق با نقصهای ذاتی در دادهها، LSM-2 میتواند به ابزاری قدرتمند برای پیشبینی و مدیریت شرایط سلامتی، ارائه توصیههای شخصیسازی شده برای بهبود تندرستی و حتی کمک به تحقیقات پزشکی در مقیاس بزرگ تبدیل شود. این پیشرفتها، مسیر را برای سیستمهای هوش مصنوعی پوشیدنی هوشمندتر و کارآمدتر هموار میکند.
با این مدل، مرزهای آنچه از دستگاههای پوشیدنی و دادههای جمعآوری شده از آنها انتظار میرود، گسترش مییابد. پتانسیل LSM-2 برای ارائه بینشهای عمیقتر و دقیقتر از سلامت فردی، حتی با وجود چالشهای رایج در جمعآوری داده، نویدبخش آیندهای است که در آن فناوری به طور یکپارچهتر و موثرتر در زندگی روزمره ما ادغام شده و به ما در مدیریت بهتر سلامتیمان کمک میکند.
تشکر و قدردانی
تحقیقات توصیفشده در اینجا کار مشترک گوگل ریسرچ، گوگل هلث، گوگل دیپمایند، و تیمهای همکار است. محققان زیر در این کار مشارکت داشتهاند: مکسول ا. خو، گیریش نارایاناسوامی، کومار آیوش، دیمیتریس اسپاتیس، شون لیائو، شیام تیلور، احمد متوالی، ا. علی حیدری، یووی ژانگ، جیک گریسون، سامی عبدالجفار، ژوهای خو، کن گو، جیکوب سانشاین، مینگ-ژر پو، یون لیو، تیم آلتوف، شریکانت نارایانان، پوشمیت کُلی، مارک مالوترا، شوتاک پاتل، یوزهه یانگ، جیمز م. ریگ، شین لیو، و دانیل مکدافی. همچنین از شرکتکنندگانی که دادههای خود را برای این مطالعه اهدا کردند، تشکر میکنیم.
منبع مقاله: LSM-2: Learning from incomplete wearable sensor data


