ظهور یادگیری ماشین (ML) منجر به توسعه برنامههای کاربردی با عملکرد بالا در طیف گستردهای از سناریوهای دنیای واقعی، از طبقهبندی جدولی گرفته تا حذف نویز تصویر، شده است. با این حال، ساخت این مدلها برای مهندسان یادگیری ماشین همچنان یک تلاش دشوار است که نیازمند آزمایشهای تکراری گسترده و مهندسی داده میباشد. برای سادهسازی این گردشهای کاری سخت و پیچیده، تحقیقات اخیر بر روی استفاده از مدلهای زبان بزرگ (LLMها) به عنوان عوامل مهندسی یادگیری ماشین (MLE) متمرکز شدهاند.
این عوامل با بهرهگیری از مهارتهای ذاتی خود در کدنویسی و استدلال، وظایف ML را به عنوان چالشهای بهینهسازی کد مفهومسازی میکنند. سپس، راهحلهای کد بالقوه را بررسی کرده و در نهایت کدهای قابل اجرا (مانند یک اسکریپت پایتون) را بر اساس توصیف وظیفه و مجموعههای داده ارائه شده، تولید میکنند. این رویکرد نوآورانه پتانسیل زیادی برای کاهش بار کاری بر دوش مهندسان ML دارد و آنها را قادر میسازد تا بر جنبههای استراتژیکتر توسعه مدل تمرکز کنند.

تصویر: عوامل مهندسی ML برای مقابله با چالشهای متنوع یادگیری ماشین با تجزیه و تحلیل توصیف وظیفه و مجموعههای دادهای که میتوانند شامل حالات مختلف باشند، ساخته شدهاند. هدف نهایی آنها شناسایی بهترین راهحل برای مشکل مورد نظر است.
علیرغم گامهای اولیه امیدوارکننده، عوامل MLE فعلی با چندین محدودیت مواجه هستند که کارایی آنها را کاهش میدهد. اولاً، وابستگی شدید آنها به دانش LLM از قبل موجود، اغلب منجر به سوگیری به سمت روشهای آشنا و پرکاربرد (مانند کتابخانه scikit-learn برای دادههای جدولی) میشود و رویکردهای خاص وظیفه که به طور بالقوه برتر هستند را نادیده میگیرند.
علاوه بر این، این عوامل معمولاً از یک استراتژی اکتشافی استفاده میکنند که کل ساختار کد را به طور همزمان در هر تکرار اصلاح میکند. این اغلب باعث میشود که عوامل به طور نابهنگام به مراحل دیگر (مانند انتخاب مدل یا تنظیم ابرپارامتر) تغییر تمرکز دهند زیرا فاقد ظرفیت اکتشاف عمیق و تکراری در اجزای خاص خط لوله هستند، مانند آزمایش جامع گزینههای مختلف مهندسی ویژگی. این محدودیتها بر نیاز به رویکردهای پیشرفتهتر در طراحی عوامل MLE تاکید میکنند که بتوانند پیچیدگیهای مهندسی یادگیری ماشین را با دقت بیشتری مدیریت کنند.
معرفی MLE-STAR: انقلابی در مهندسی یادگیری ماشین
در مقاله اخیر ما، MLE-STAR را معرفی میکنیم، یک عامل مهندسی ML نوین که جستجوی وب و پالایش هدفمند بلوکهای کد را ادغام میکند. برخلاف گزینههای دیگر، MLE-STAR با جستجو در وب برای یافتن مدلهای مناسب برای ایجاد یک پایه محکم، به چالشهای ML میپردازد. سپس، این پایه را با آزمایش اینکه کدام بخشهای کد مهمتر هستند، با دقت بهبود میبخشد.
MLE-STAR همچنین از یک روش جدید برای ترکیب چندین مدل با یکدیگر برای نتایج بهتر استفاده میکند. این رویکرد بسیار موفق بوده است و در ۶۳٪ از مسابقات Kaggle در MLE-Bench-Lite مدال کسب کرده که به طور قابل توجهی از سایر جایگزینها عملکرد بهتری داشته است. این دستاورد، توانایی MLE-STAR را در ارائه راهحلهای پیشرفته و کارآمد برای مسائل پیچیده یادگیری ماشین برجسته میکند.
برای تولید کد راهحل اولیه، MLE-STAR از جستجوی وب برای بازیابی رویکردهای مرتبط و به طور بالقوه پیشرفته که میتواند برای ساخت یک مدل موثر باشد، استفاده میکند. برای بهبود راهحل، MLE-STAR یک بلوک کد خاص را که نشاندهنده یک جزء متمایز از خط لوله ML است، مانند مهندسی ویژگی یا ساخت مجموعه، استخراج میکند. سپس، بر روی بررسی استراتژیهای متناسب با آن جزء تمرکز کرده و تلاشهای قبلی را به عنوان بازخورد در نظر میگیرد. برای شناسایی بلوک کد با بیشترین تأثیر بر عملکرد، MLE-STAR یک مطالعه حذف انجام میدهد که سهم هر جزء ML را ارزیابی میکند. این فرآیند پالایش تکرار میشود و بلوکهای کد مختلف را اصلاح میکند.
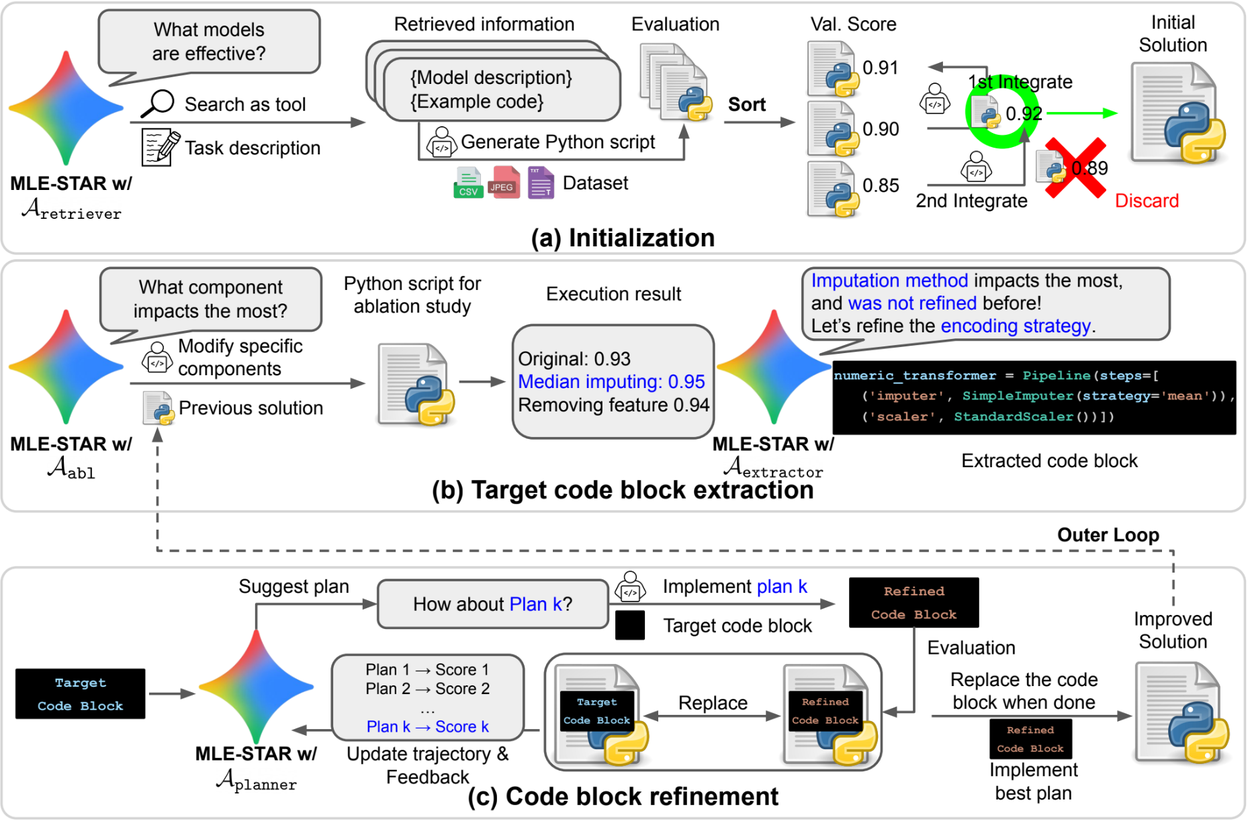
تصویر: نمای کلی. (الف) MLE-STAR با استفاده از جستجوی وب برای یافتن و گنجاندن مدلهای خاص وظیفه در یک راهحل اولیه آغاز میشود. (ب) برای هر مرحله پالایش، یک مطالعه حذف انجام میدهد تا بلوک کد با بیشترین تأثیر بر عملکرد را شناسایی کند. (ج) بلوک کد شناسایی شده سپس بر اساس برنامههای پیشنهادی LLM، که استراتژیهای مختلف را با استفاده از بازخورد آزمایشهای قبلی بررسی میکنند، تحت پالایش تکراری قرار میگیرد. این فرآیند انتخاب و پالایش بلوکهای کد هدف تکرار میشود، جایی که راهحل بهبود یافته از (ج) نقطه شروع برای مرحله پالایش بعدی در (ب) میشود.
علاوه بر این، ما یک روش جدید برای تولید مجموعهها (ensembles) ارائه میدهیم. MLE-STAR ابتدا چندین راهحل کاندید را پیشنهاد میکند. سپس، به جای تکیه بر یک مکانیسم رأیگیری ساده بر اساس نمرات اعتبارسنجی، MLE-STAR این کاندیداها را در یک راهحل واحد و بهبود یافته با استفاده از یک استراتژی مجموعه پیشنهادی توسط خود عامل ادغام میکند. این استراتژی مجموعه بر اساس عملکرد استراتژیهای قبلی به صورت تکراری پالایش میشود. این رویکرد به MLE-STAR امکان میدهد تا از قدرت ترکیبی چندین مدل بهرهبرداری کند و به طور قابل توجهی دقت و پایداری پیشبینیها را بهبود بخشد.
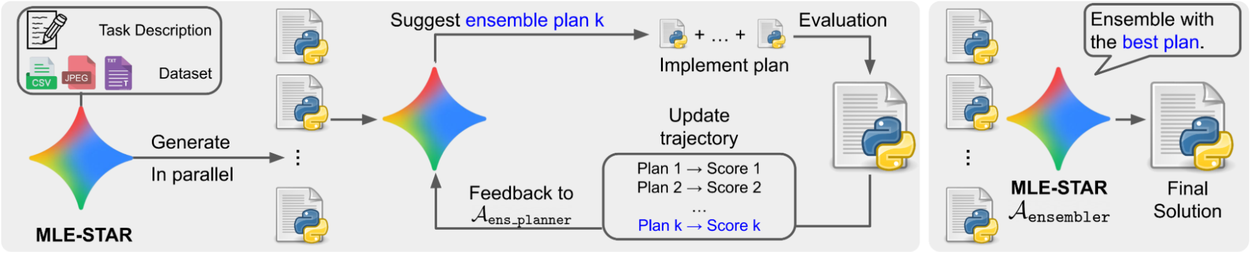
تصویر: ترکیب راهحلها: MLE-STAR استراتژیهای مجموعه خود را در تلاشهای متوالی پالایش میکند و چندین راهحل تولید شده موازی را به طور کارآمد در یک راهحل واحد و بهبود یافته ترکیب میکند.
نکته آخر، MLE-STAR سه ماژول اضافی را برای افزایش پایداری خود در بر میگیرد: (۱) یک عامل اشکالزدایی، (۲) یک بررسی کننده نشت داده، و (۳) یک بررسی کننده استفاده از داده. برای عامل اشکالزدایی، اگر اجرای یک اسکریپت پایتون خطایی را ایجاد کند که منجر به یک رکورد (مانند یک Traceback) شود، MLE-STAR از یک ماژول اشکالزدایی برای تلاش برای تصحیح استفاده میکند. این قابلیت به عامل اجازه میدهد تا به صورت خودکار مشکلات کد را تشخیص داده و رفع کند، که زمان توسعه را به شدت کاهش میدهد.
در مورد بررسی کننده نشت داده، ما مشاهده کردهایم که اسکریپتهای پایتون تولید شده توسط LLM خطر نشت داده را به همراه دارند، برای مثال، با دسترسی نامناسب به اطلاعات از یک مجموعه داده آزمایشی در طول آمادهسازی دادههای آموزشی. برای رفع این مشکل، ما یک عامل بررسی کننده معرفی کردهایم که اسکریپت راهحل را قبل از اجرای آن تجزیه و تحلیل میکند. این تضمین میکند که یکپارچگی دادهها حفظ شده و از خطاهای حیاتی که میتوانند بر عملکرد مدل تأثیر بگذارند، جلوگیری شود.
در مورد بررسی کننده استفاده از داده، ما متوجه شدهایم که اسکریپتهای تولید شده توسط LLM گاهی اوقات از استفاده از تمام منابع داده ارائه شده غفلت میکنند و صرفاً بر فرمتهای ساده مانند CSV تمرکز میکنند. برای اطمینان از استفاده از تمام دادههای مرتبط ارائه شده، MLE-STAR شامل یک عامل بررسی کننده استفاده از داده است. این ماژول اطمینان میدهد که هیچ داده ارزشمندی نادیده گرفته نمیشود، که میتواند به طور قابل توجهی به بهبود کیفیت و دقت مدل نهایی کمک کند. این سه ماژول به طور جمعی، MLE-STAR را به یک ابزار بسیار قابل اعتماد و جامع برای مهندسی ML تبدیل میکنند.
ارزیابیها و نتایج پیشرو
برای اعتبارسنجی اثربخشی آن، ما ارزیابیهای جامعی از MLE-STAR با استفاده از مسابقات Kaggle در MLE-Bench-Lite انجام دادیم. در اینجا، ما از یک عامل اضافی استفاده کردیم که توصیف وظیفه و راهحل نهایی را به عنوان ورودی میگیرد و کدی را تولید میکند که شامل بارگذاری نمونه آزمایشی و ایجاد یک فایل ارسال است. این فرآیند تضمین میکند که ارزیابیها عادلانه و استاندارد هستند و نتایج قابل مقایسه با سایر روشها را فراهم میکند.

تصویر: نتایج اصلی از MLE-Bench-Lite. امتیازات نشاندهنده میانگین درصد دستاوردها در مسابقات Kaggle در MLE-Bench-Lite است.
نتایج تجربی ارائه شده در شکل بالا نشان میدهد که MLE-STAR، با نیاز به حداقل تلاش انسانی (مثلاً تعریف پرامپتهای اولیه که قابل تعمیم به هر وظیفهای هستند)، به طور قابل توجهی از جایگزینهای قبلی، از جمله آنهایی که نیازمند کار دستی برای جمعآوری استراتژیها از Kaggle هستند، عملکرد بهتری دارد. این نشاندهنده کارایی و خودکار بودن بالای MLE-STAR در مقایسه با روشهای سنتی است.
به طور خاص، MLE-STAR به دستاورد قابل توجهی در هر نوع مدال دست یافته و آن را از ۲۵.۸٪ به ۶۳.۶٪ در مقایسه با بهترین پایه عملکرد (AIDE) بهبود بخشیده است. این پیشرفت چشمگیر در عملکرد، جایگاه MLE-STAR را به عنوان یک عامل مهندسی یادگیری ماشین پیشرو و قدرتمند تثبیت میکند که قادر به دستیابی به نتایج برتر در سناریوهای رقابتی است.
تحلیل عمیق دستاوردهای MLE-STAR
برای درک منابع افزایش عملکرد MLE-STAR، ما چندین تحلیل را از دیدگاههای مختلف انجام دادیم. در اینجا، ما (۱) انواع مدلهای ML که MLE-STAR از آنها استفاده میکند، (۲) چگونگی گسترش MLE-STAR با مداخله انسانی، و (۳) چگونگی بهبود عملکرد MLE-STAR توسط بررسیکنندههای اضافی نشت داده و استفاده از داده را بررسی کردیم.
استفاده از مدل: دو عامل MLE را در نظر بگیرید. AIDE عمدتاً از ResNet برای طبقهبندی تصویر استفاده میکند. با این حال، ResNet که در سال ۲۰۱۵ منتشر شد، اکنون منسوخ شده در نظر گرفته میشود و میتواند منجر به عملکرد نامطلوب شود. در مقابل، MLE-STAR عمدتاً از مدلهای جدیدتر و رقابتیتر مانند EfficientNet یا ViT استفاده میکند که منجر به افزایش عملکرد مشاهده شده است. این نشان میدهد که قابلیت MLE-STAR در بازیابی و استفاده از مدلهای پیشرفته از طریق جستجوی وب، یک مزیت کلیدی است.
مداخله انسانی: MLE-STAR به راحتی مدلهای حتی جدیدتر را با حداقل مداخله انسانی به کار میگیرد. در حالی که MLE-STAR به طور خودکار یک توصیف مدل را با استفاده از جستجوی وب میسازد، یک توسعه طبیعی شامل استفاده از تخصص انسانی برای این ساختار است. با افزودن دستی یک توصیف مدل برای RealMLP، MLE-STAR با موفقیت کد آموزشی آن را در چارچوب ادغام میکند، مدلی که قبلاً بازیابی نشده بود. این قابلیت انعطافپذیری، امکان همکاری بین عامل و مهندس انسانی را فراهم میکند و به راهحلهای بهینهتری منجر میشود.
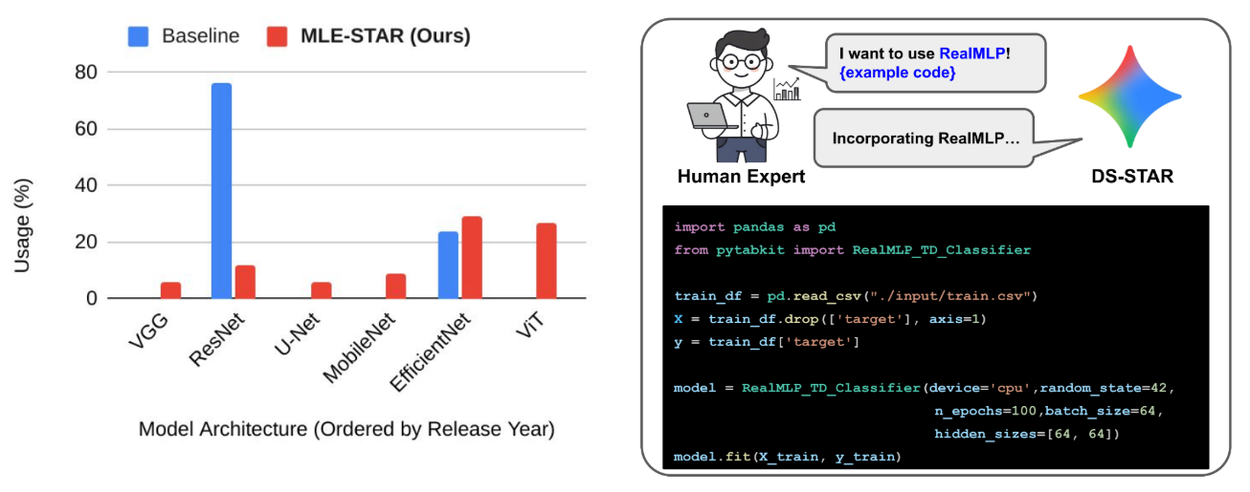
تصویر: سمت چپ: استفاده از مدل (%) در مسابقات طبقهبندی تصویر. سمت راست: نمایش مداخله انسانی: MLE-STAR کد آموزشی یک مدل را بر اساس یک توصیف مدل دستی ادغام میکند.
سوءرفتار LLM و تصحیحات: ما مشاهده کردیم که در حالی که کد تولید شده توسط LLM به درستی اجرا میشد، محتوای آن گاهی اوقات غیرواقعی بود و دچار توهم میشد. برای مثال، شکل زیر (سمت چپ) یک رویکرد غیرعملی را نشان میدهد که در آن دادههای آزمایشی با استفاده از آمار خودشان پیشپردازش میشوند. از آنجایی که دادههای آزمایشی باید دیده نشده باقی بمانند، تصحیح در کد ضروری است، که MLE-STAR برای شناسایی چنین مسائلی و پالایش اسکریپت تولید شده در صورت تشخیص مشکل، از یک بررسیکننده نشت داده استفاده میکند. این ویژگی حیاتی، اطمینان از اعتبار و صحت راهحلهای تولید شده را فراهم میکند و از خطاهای بحرانی در فرآیند یادگیری ماشین جلوگیری میکند.
ما همچنین مشاهده کردیم که LLMها اغلب اسکریپتهایی را تولید میکنند که برخی از منابع داده ارائه شده را نادیده میگیرند. برای رفع این مشکل، MLE-STAR از یک بررسیکننده استفاده از داده استفاده میکند که توصیف وظیفه را مجدداً بررسی میکند تا اطمینان حاصل شود که تمام دادههای ارائه شده استفاده میشوند. همانطور که در (سمت راست) نشان داده شده است، این طراحی MLE-STAR را قادر میسازد تا دادههایی که قبلاً نادیده گرفته شده بودند را نیز در بر گیرد. این قابلیتها به طور چشمگیری پایداری و جامعیت راهحلهای MLE-STAR را افزایش میدهند، و آن را به یک ابزار قابل اعتماد برای وظایف پیچیده ML تبدیل میکنند.

تصویر: سمت چپ: بررسیکننده نشت داده MLE-STAR از پیشپردازش مناسب اطمینان حاصل میکند. سمت راست: بررسیکننده استفاده از داده MLE-STAR اطلاعاتی که قبلاً استفاده نشده بودند را شناسایی و ادغام میکند.
نتیجهگیری
ما MLE-STAR را پیشنهاد کردیم، یک عامل نوین مهندسی یادگیری ماشین که برای وظایف متنوع ML طراحی شده است. ایده اصلی ما استفاده از جستجوی وب برای بازیابی مدلهای موثر و سپس بررسی استراتژیهای مختلف با هدف اجزای خاص خط لوله ML برای بهبود راهحل است. اثربخشی MLE-STAR با کسب مدال در ۶۳٪ (۳۶٪ از آنها مدال طلا هستند) از مسابقات Kaggle MLE-Bench-Lite اعتبارسنجی شده است. این موفقیت نشاندهنده برتری و کارایی MLE-STAR در محیطهای رقابتی است.
با خودکارسازی وظایف پیچیده ML، MLE-STAR میتواند مانع ورود برای افراد و سازمانهایی که به دنبال بهرهبرداری از ML هستند را کاهش دهد و به طور بالقوه نوآوری را در بخشهای مختلف تقویت کند. علاوه بر این، با توجه به اینکه مدلهای پیشرفته به طور مداوم بهروزرسانی و بهبود مییابند، انتظار میرود عملکرد راهحلهای تولید شده توسط MLE-STAR به طور خودکار افزایش یابد. این به دلیل سازگاری ذاتی چارچوب ما است که از یک موتور جستجو برای بازیابی مدلهای موثر از وب برای شکلدهی راهحلهای خود استفاده میکند. این ویژگی تضمین میکند که MLE-STAR با پیشرفت حوزه ML، به ارائه راهحلهای بهتر ادامه میدهد.
در نهایت، توسعهدهندگان و محققان اکنون میتوانند پروژههای یادگیری ماشین خود را با استفاده از پایگاه کد متنباز تازه منتشر شده MLE-STAR که با Agent Development Kit (ADK) ساخته شده است، سرعت بخشند. این دسترسی عمومی به ابزار، همکاری و نوآوری را در جامعه یادگیری ماشین تسهیل میکند و به افراد بیشتری امکان میدهد تا از قابلیتهای پیشرفته این عامل بهرهمند شوند.
سپاسگزاری
از مشارکتهای Jiefeng Chen, Jinwoo Shin, Sercan O Arik, Raj Sinha, و Tomas Pfister صمیمانه سپاسگزاریم.
منبع مقاله: Google Research Blog


