مقدمه
دستگاههای پوشیدنی با امکان جمعآوری مداوم سیگنالهای فیزیولوژیکی و رفتاری مانند ضربان قلب، فعالیت، دما و رسانایی پوست، نظارت بر سلامت را متحول کردهاند. این دستگاهها قابلیتهای بینظیری را برای رصد وضعیت سلامت افراد در طول شبانهروز فراهم میآورند و دادههای ارزشمندی را برای تحلیلهای هوش مصنوعی تولید میکنند. با این حال، دادههای واقعی تولید شده توسط این دستگاهها به دلیل خرابی حسگر، برداشتن دستگاه، شارژ، آرتیفکتهای حرکتی، حالتهای صرفهجویی در باتری و سایر وقفهها، بسیار مستعد نقص هستند. این نقصها میتوانند به صورت شکافهای طولانی در دادهها ظاهر شوند که تحلیل و پردازش آنها را دشوار میسازد.
این وضعیت، چالش قابل توجهی را برای یادگیری خود نظارت شده (SSL) و مدلهای بنیادی ایجاد میکند که معمولاً انتظار جریانهای داده کامل و منظم را دارند. مدلهای هوش مصنوعی سنتی اغلب برای کار با دادههای کامل طراحی شدهاند و در مواجهه با نقص، کارایی خود را از دست میدهند. راه حلهای گذشته برای مقابله با این مشکل، اغلب به پر کردن داده (imputation) یا کنار گذاشتن نمونههای ناقص متکی بودند. این روشها، اگرچه میتوانستند به صورت موقت مشکل را حل کنند، اما خطر معرفی سوگیری یا هدر دادن اطلاعات ارزشمند را به همراه داشتند، چرا که اطلاعات مهمی ممکن بود در بخشهای از دست رفته داده نهفته باشند.
تیمی از محققان گوگل DeepMind برای رفع این محدودیتها، چارچوب LSM-2 (مدل حسگر بزرگ 2) را معرفی کردند. این چارچوب با استراتژی جدید ماسکگذاری تطبیقی و موروثی (AIM) همراه است که به طور مستقیم به مسائل نقص داده میپردازد. هدف اصلی LSM-2 یادگیری بازنماییهای قوی از دادههای ناقص حسگرهای پوشیدنی بدون نیاز به پر کردن صریح دادهها است. این رویکرد نوآورانه، پارادایم جدیدی را در پردازش دادههای سلامت در دنیای واقعی معرفی میکند، جایی که پیشبینی پذیری و یکپارچگی دادهها اغلب یک استثنا هستند تا یک قاعده. در ادامه، نوآوریهای فنی، نتایج تجربی و بینشهای کلیدی حاصل از این پیشرفت را بررسی خواهیم کرد.
چالش: نقص دادههای پوشیدنی
یکی از بزرگترین موانع در استفاده از دادههای دستگاههای پوشیدنی برای مدلسازی هوش مصنوعی، ماهیت ناقص و پراکنده این دادهها در دنیای واقعی است. این نقص نه تنها نادر نیست، بلکه در واقع یک ویژگی ذاتی این نوع دادهها محسوب میشود. در یک مجموعه داده بزرگ شامل 1.6 میلیون نمونه داده پوشیدنی یک روزه (1440 دقیقه)، مشاهده شد که 0% از نمونهها کاملاً کامل بودند؛ این بدان معناست که نقص دادهها فراگیر است و اغلب به صورت شکافهای طولانی و نه صرفاً افتهای تصادفی، ساختار یافته است.
این وضعیت نشاندهده واقعیت جمعآوری دادهها در محیطهای روزمره است، جایی که عوامل متعددی میتوانند منجر به از دست رفتن اطلاعات شوند. فهم دقیق این الگوهای نقص برای توسعه مدلهای هوش مصنوعی که بتوانند با چنین چالشهایی مقابله کنند، حیاتی است. دلایل رایج نقص داده شامل موارد زیر است که اغلب در زندگی روزمره کاربران دستگاههای پوشیدنی مشاهده میشود:
* **خاموش بودن دستگاه**: کاربر ممکن است دستگاه را برای شارژ از بدن خود خارج کند یا به سادگی آن را نپوشد. این حالت منجر به وقفههای طولانی در جمعآوری داده میشود.
* **غیرفعال شدن انتخابی حسگر**: گاهی اوقات، برای صرفهجویی در مصرف انرژی یا به دلایل خاص عملیاتی، برخی از حسگرها به طور موقت غیرفعال میشوند. این امر میتواند منجر به از دست رفتن دادهها برای یک حسگر خاص در طول یک دوره زمانی شود.
* **آرتیفکتهای حرکتی یا نویز محیطی**: حرکتهای ناگهانی، فعالیتهای فیزیکی شدید، یا تداخلهای محیطی میتوانند دقت حسگر را کاهش داده و باعث تولید دادههای بیکیفیت یا از دست رفتن آنها شوند.
* **قرائتهای خارج از محدوده یا از نظر فیزیولوژیکی غیرممکن**: دادههایی که از محدوده نرمال خارج هستند یا از نظر فیزیولوژیکی نامعقول به نظر میرسند، ممکن است در مرحله پیشپردازش فیلتر شوند. این فیلتر کردن، هرچند برای حفظ کیفیت داده ضروری است، اما به حجم نقص داده میافزاید.
این چالشها به این معناست که بسیاری از الگوهای فیزیولوژیکی مرتبط با بالینی (مانند ریتمهای شبانهروزی، تغییرپذیری ضربان قلب) که نیاز به تحلیل دنبالههای طولانی دارند، تقریباً همیشه با نقص داده مواجه خواهند شد. مدلهای سنتی که برای دادههای کامل طراحی شدهاند، در مواجهه با این حجم از نقص، کارایی خود را از دست میدهند و نمیتوانند بینشهای دقیقی را از دادههای واقعی استخراج کنند. این همان نقطهای است که LSM-2 به دنبال پر کردن آن است.
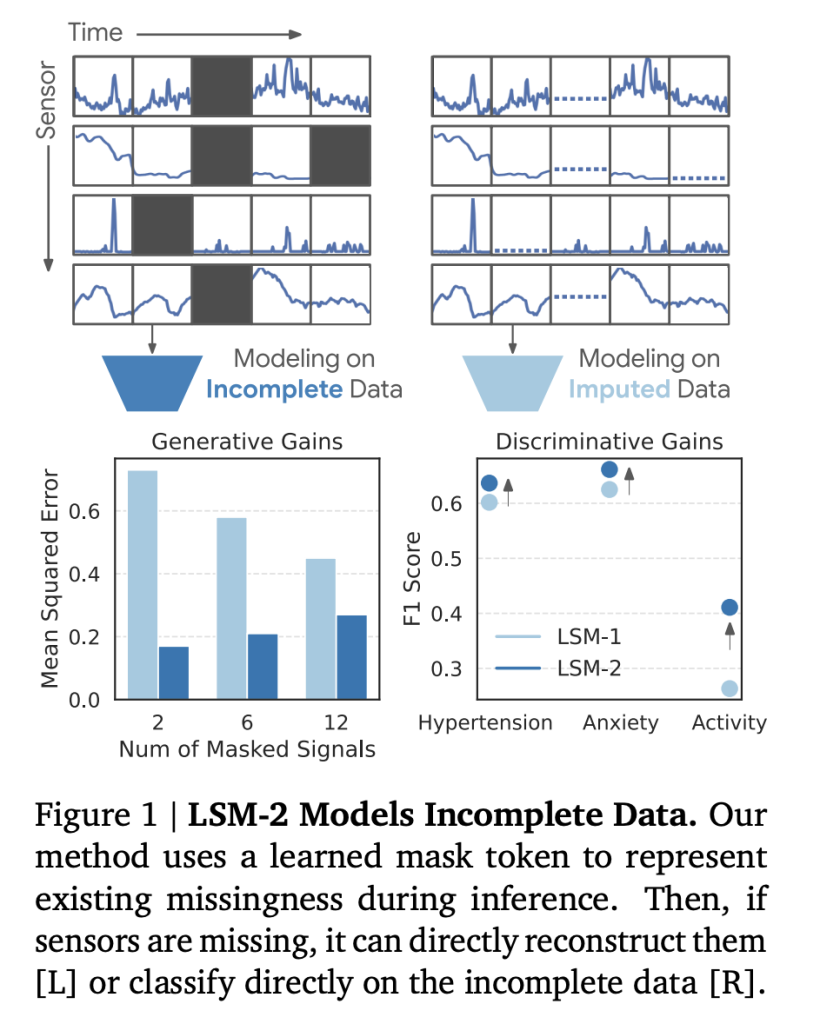
ماسکگذاری تطبیقی و موروثی (AIM): رویکرد فنی
چارچوب LSM-2 که توسط محققان گوگل DeepMind معرفی شده است، یک پاسخ مستقیم و نوآورانه به چالش نقص داده در سنسورهای پوشیدنی ارائه میدهد. این مدل به همراه استراتژی جدید ماسکگذاری تطبیقی و موروثی (AIM)، به طور مستقیم به مسائل مربوط به دادههای ناقص میپردازد و قادر است بازنماییهای قوی را از دادههای حسگرهای پوشیدنی بدون نیاز به هیچ گونه پر کردن صریح دادهها یاد بگیرد. این نوآوری، یک تغییر پارادایم اساسی در نحوه پردازش و استفاده از دادههای سلامت در دنیای واقعی است.
هدف اصلی AIM، توانمندسازی مدل برای یادگیری از دادهها به همان صورتی است که جمعآوری میشوند، یعنی با تمام نقصهایشان. این رویکرد به مدل اجازه میدهد تا نه تنها از دادههای موجود بهره ببرد، بلکه از ساختار و توزیع نقصها نیز درس بگیرد، که این امر منجر به ایجاد بازنماییهای قویتر و کاربردیتر میشود. این مدل به طور خاص برای محیطهایی طراحی شده است که در آن پیشبینیپذیری و یکپارچگی دادهها اغلب یک استثنا هستند تا یک قاعده.
مفاهیم کلیدی
AIM با ادغام دو نوع ماسکگذاری، قادر به یادگیری قویتر و مؤثرتر است:
* **ماسک موروثی (Inherited Mask)**: این ماسک توکنهایی را که مربوط به نقص واقعی در دادههای حسگر هستند، علامتگذاری میکند. این نشاندهنده بخشهایی از داده است که به دلیل عوامل خارجی، مانند خاموش بودن دستگاه یا خرابی حسگر، از ابتدا وجود نداشتهاند.
* **ماسک مصنوعی (Artificial Mask)**: این ماسک به صورت تصادفی توکنهای مشاهده شده را ماسکگذاری میکند تا اهداف بازسازی را برای پیشآموزش خود نظارت شده (self-supervised pretraining) فراهم کند. این فرایند به مدل آموزش میدهد که چگونه حتی دادههای از دست رفته را پیشبینی کند و درک عمیقتری از روابط داخلی دادهها به دست آورد.
این دو نوع ماسک، یعنی ماسک موروثی و مصنوعی، با هم ترکیب شده و توسط یک ساختار رمزگذار-رمزگشای مبتنی بر ترانسفورمر مدیریت میشوند. این ساختار مدل را قادر میسازد تا:
* مستقیماً از دادههای ناقص و بدون پر کردن یاد بگیرد. این قابلیت به مدل اجازه میدهد تا با دادههای خام و بدون پردازش اولیه کار کند، که این امر پیچیدگی و نیاز به پیشپردازشهای پرهزینه را کاهش میدهد.
* به صورت پویا با نقصهای دنیای واقعی در طول استنتاج (inference) سازگار شود. این بدان معناست که مدل میتواند حتی در شرایطی که در زمان واقعی دادهها ناقص میشوند، عملکرد پایداری داشته باشد.
* بازنماییهایی را تولید کند که نسبت به شکافهای جزئی و سیستماتیک دادهها مقاوم هستند. این امر به مدل انعطافپذیری لازم را برای مقابله با انواع مختلف نقص داده میدهد.
این قابلیت تطبیقپذیری، LSM-2 را از راهحلهای سنتی که به دادههای کامل یا پر شده تکیه دارند، متمایز میکند. این مدل میتواند با نویز و عدم قطعیت ذاتی در دادههای پوشیدنی سروکار داشته باشد و نتایج قابل اعتمادتر و قابل تعمیمتری را ارائه دهد که برای کاربردهای عملی در حوزه سلامت بسیار حیاتی است.
استراتژیهای ماسکگذاری برای پیشآموزش
برای آموزش مدل به منظور درک و مدیریت نقص دادهها، از چندین استراتژی ماسکگذاری هدفمند استفاده شد تا مدل بتواند با طیف وسیعی از سناریوهای نقص داده آشنا شود:
* **پر کردن تصادفی (Random Imputation)**: در این استراتژی، 80% از توکنها به صورت تصادفی حذف میشوند، که شبیهسازی نویز حسگر را به همراه دارد. این رویکرد به مدل کمک میکند تا یاد بگیرد چگونه با قطعات کوچک و تصادفی دادههای از دست رفته کنار بیاید و توانایی مدل را در پر کردن جزئیات کوچک افزایش میدهد.
* **برشهای زمانی (Temporal Slices)**: در این روش، 50% از پنجرههای زمانی به طور کامل حذف میشوند (همه حسگرها در دورههای تصادفی از دست رفتهاند). این استراتژی، وقفههای طولانیتر و سیستماتیکتر را که معمولاً در استفاده از دستگاههای پوشیدنی رخ میدهد، شبیهسازی میکند، مانند زمانی که دستگاه برای چند ساعت از بدن جدا میشود.
* **برشهای حسگر (Sensor Slices)**: در این استراتژی، 50% از کانالهای حسگر در طول روز (مدلسازی دورههای غیرفعال بودن حسگرهای انتخابی) حذف میشوند. این حالت، سناریوهایی را در بر میگیرد که یک حسگر خاص ممکن است به طور موقت یا دائمی از کار بیفتد، مثلاً به دلیل خرابی فنی یا صرفهجویی در باتری.
AIM کارایی ماسکگذاری حذف (dropout masking)، که توکنها را به طور کامل از محاسبات حذف میکند، و انعطافپذیری ماسکگذاری توجه (attention masking)، که از نقصهای پویا و متغیر پشتیبانی میکند، را ترکیب میکند. این ترکیب به مدل امکان میدهد تا دنبالههای ورودی طولانی (یک روز کامل، بیش از 3000 توکن) را مقیاسبندی کند. این ترکیب هوشمندانه تضمین میکند که مدل نه تنها میتواند دادههای از دست رفته را پیشبینی کند، بلکه میتواند درک عمیقتری از روابط زمانی و فضایی بین حسگرهای مختلف پیدا کند و بدین ترتیب، حتی با دادههای ناقص، به نتایج دقیق و معناداری دست یابد. این روش به LSM-2 این قابلیت را میدهد که در برابر شرایط واقعی و غیرایدهآل جمعآوری داده، بسیار مقاوم باشد.
جزئیات مجموعه داده و پیشآموزش
برای آموزش و ارزیابی مدل LSM-2، از یک مجموعه داده وسیع و پیچیده از اطلاعات حسگرهای پوشیدنی استفاده شده است. این مجموعه داده از اهمیت ویژهای برخوردار است، زیرا تنوع و مقیاس آن به مدل امکان میدهد تا الگوهای پیچیده و متنوعی را در سیگنالهای فیزیولوژیکی و رفتاری انسان شناسایی کرده و یاد بگیرد. جمعآوری دادهها با این وسعت و تنوع، یک گام مهم در توسعه مدلهای هوش مصنوعی کاربردی برای حوزه سلامت است.
* **مقیاس**: دادهها شامل 40 میلیون ساعت اطلاعات حسگر چندحالته (multimodal) یک روزه هستند که از 60,440 شرکتکننده جمعآوری شدهاند. این جمعآوری بین مارس و مه 2024 انجام شده است. حجم بیسابقه این دادهها به مدل اجازه میدهد تا از طیف گستردهای از رفتارها و واکنشهای فیزیولوژیکی بیاموزد، که این امر برای تعمیمپذیری مدل به جمعیتهای متنوع و سناریوهای مختلف بسیار حیاتی است.
* **حسگرها**: دادهها از حسگرهای مختلفی مانند فوتوپلتیسموگرافی (PPG) برای اندازهگیری ضربان قلب، شتابسنج برای ردیابی حرکت و فعالیت، فعالیت الکترودرمال (EDA) برای سنجش استرس و واکنشهای پوستی، دمای پوست برای پایش سلامت عمومی و ارتفاعسنج برای تشخیص تغییرات ارتفاع جمعآوری شدهاند. هر دستگاه ویژگیهای جمعآوری شده دقیقهای را در یک پنجره 24 ساعته ارائه میدهد. این تنوع حسگرها امکان ایجاد یک دید جامع از وضعیت کاربر را فراهم میکند و به مدل کمک میکند تا روابط پیچیده بین سیگنالهای مختلف را کشف کند.
* **تنوع جمعیتشناختی**: شرکتکنندگان در این مطالعه در طیف وسیعی از سنین (18 تا 96 سال)، جنسیتها و کلاسهای شاخص توده بدنی (BMI) قرار داشتند. این تنوع جمعیتشناختی به مدل کمک میکند تا برای گروههای مختلف کاربران تعمیمپذیر باشد و سوگیریهای احتمالی را که ممکن است از دادههای نامتوازن ناشی شوند، کاهش دهد. این امر به مدل قدرت بیشتری برای کاربردهای بالینی در جمعیتهای متنوع میبخشد.
* **دادههای برچسبگذاری شده پاییندستی**: برای ارزیابی عملکرد مدل در وظایف خاص، از دادههای برچسبگذاری شده استفاده شده است. این شامل یک مطالعه متابولیک برای پیشبینی فشار خون بالا و اضطراب با 1,250 کاربر برچسبگذاری شده، و همچنین یک مجموعه داده برای تشخیص فعالیت شامل 20 کلاس فعالیت و 104,086 رویداد است. این دادههای برچسبگذاری شده برای اعتبارسنجی قابلیتهای مدل در پیشبینی نتایج بالینی و رفتاری در دنیای واقعی ضروری هستند.
این مجموعه داده جامع و روشمند، پایهای قوی برای آموزش LSM-2 فراهم میکند، و به آن امکان میدهد تا با چالشهای ذاتی دادههای پوشیدنی مقابله کرده و در عین حال، بینشهای عمیقی را برای کاربردهای عملی در حوزه سلامت ارائه دهد.
ارزیابی و نتایج
عملکرد مدل LSM-2 مبتنی بر AIM بر روی طیف وسیعی از وظایف پاییندستی ارزیابی شد تا کارایی و قابلیت تعمیم آن در سناریوهای مختلف دنیای واقعی سنجیده شود. این ارزیابیهای جامع، توانایی مدل را در مقابله با چالشهای مختلف در دادههای ناقص پوشیدنی به خوبی نشان میدهند و اهمیت رویکرد جدید را برجسته میکنند.
وظایف پاییندستی
LSM-2 مبتنی بر AIM بر روی چندین وظیفه مهم ارزیابی شد تا تواناییهای آن در هر دو زمینه طبقهبندی و رگرسیون، و همچنین در بازیابی دادههای از دست رفته، مشخص شود:
* **طبقهبندی (Classification)**: این مدل برای تشخیص فشار خون بالا به صورت باینری، اضطراب، و همچنین تشخیص 20 کلاس فعالیت مختلف (مانند پیادهروی، دویدن، خواب) مورد آزمایش قرار گرفت. این وظایف نیازمند توانایی مدل در طبقهبندی دقیق الگوهای پیچیده در دادهها هستند.
* **رگرسیون (Regression)**: LSM-2 برای پیشبینی سن و شاخص توده بدنی (BMI) افراد بر اساس دادههای حسگرهای پوشیدنی ارزیابی شد. این وظایف نشاندهنده توانایی مدل در استخراج اطلاعات کمی و پیوسته از دادهها هستند.
* **تولیدی (Generative)**: مدل همچنین برای بازیابی دادههای حسگر از دست رفته مورد آزمایش قرار گرفت، از جمله پر کردن تصادفی دادهها (random imputation) و شکافهای بزرگ زمانی یا سیگنال (temporal/signal gaps). این قابلیت برای کاربردهای عملی که در آن بازیابی دادههای ناقص ضروری است، بسیار مهم است.
نتایج کمی
جدول زیر مقایسه عملکرد بهترین مدل LSM-1 و LSM-2 با AIM را در وظایف مختلف نشان میدهد. متریکهای استفاده شده شامل F1-score برای طبقهبندی (هرچه بالاتر، بهتر) و ضریب همبستگی (Corr) برای رگرسیون (هرچه بالاتر، بهتر)، و میانگین مربعات خطا (MSE) برای وظایف تولیدی (هرچه کمتر، بهتر) است:
| وظیفه | متریک | بهترین LSM-1 | LSM-2 با AIM | بهبود |
| :—————- | :———- | :———- | :———— | :——- |
| فشار خون بالا | F1 | 0.640 | 0.651 | +1.7% |
| تشخیص فعالیت | F1 | 0.470 | 0.474 | +0.8% |
| BMI (رگرسیون) | Corr | 0.667 | 0.673 | +1.0% |
| پر کردن تصادفی (80%) | MSE (↓) | 0.30 | 0.20 | 33% خطای کمتر |
| بازیابی 2 سیگنال | MSE (↓) | 0.73 | 0.17 | 77% خطای کمتر |
این نتایج به وضوح نشاندهنده پیشرفت قابل توجه LSM-2 در مدیریت دادههای ناقص است، به خصوص در وظایف بازیابی سیگنال که کاهش خطای قابل توجهی را نشان میدهد. به عنوان مثال، در بازیابی دو سیگنال، خطای MSE توسط LSM-2 به میزان 77% نسبت به LSM-1 کاهش یافته است که نشاندهنده توانایی فوقالعاده مدل در بازسازی دقیق دادههای از دست رفته است.
* **مقاومت در برابر نقص هدفمند**: یکی از مهمترین یافتهها، مقاومت بالای LSM-2 در برابر نقصهای هدفمند بود. هنگامی که حسگرهای خاص یا پنجرههای زمانی به طور مصنوعی حذف شدند، LSM-2 با AIM به طور متوسط 73% کاهش عملکرد کمتری را نسبت به LSM-1 تجربه کرد. به عنوان مثال، کاهش F1 پس از حذف دادههای شتابسنجی برای تشخیص فعالیت در LSM-2 برابر با 57%- بود، در حالی که برای LSM-1 برابر با 71%- بود. علاوه بر این، LSM-2 پس از حذف، 47% F1 مطلق بالاتری را حفظ کرد، که نشاندهنده توانایی مدل در حفظ عملکرد در شرایط دادههای بسیار ناقص است.
* **همبستگی بالینی**: عملکرد مدل در شرایط مختلف نقص، با انتظارات حوزه بالینی مطابقت داشت. به عنوان مثال، حذف بیوسیگنالهای شبانه به طور قابل توجهی دقت پیشبینی فشار خون بالا و اضطراب را کاهش داد. این یافته، ارزش تشخیصی واقعی دادههای شبانه را که برای تشخیص بسیاری از بیماریها حیاتی هستند، منعکس میکند و به اعتباردهی قابلیتهای بالینی مدل میافزاید.
* **مقیاسپذیری**: LSM-2 در مقایسه با LSM-1 از نظر تعداد سوژهها، حجم دادهها، نیازهای محاسباتی و اندازه مدل، مقیاسپذیری بهتری از خود نشان داد. نکته قابل توجه این است که هیچ اشباعی در بهبود عملکرد با افزایش مقیاس مشاهده نشد. این بدان معناست که مدل پتانسیل رشد و بهبود بیشتر با افزایش حجم دادهها و منابع محاسباتی را دارد، که آن را برای کاربردهای آینده در مقیاس بزرگ بسیار امیدوارکننده میسازد.
بینشهای فنی
LSM-2 با ماسکگذاری تطبیقی و موروثی (AIM) چندین نوآوری فنی مهم را به همراه دارد که آن را از مدلهای پیشین متمایز میکند و جایگاه آن را به عنوان یک مدل بنیادی پیشرو در حوزه دادههای پوشیدنی تثبیت میکند. این بینشها به درک عمیقتر از چگونگی دستیابی مدل به چنین عملکرد بالایی کمک میکنند.
* **مدیریت مستقیم نقصهای دنیای واقعی**: LSM-2 اولین مدل بنیادی پوشیدنی است که مستقیماً بر روی دادههای ناقص و بدون نیاز به پر کردن صریح دادهها آموزش و ارزیابی شده است. این رویکرد به مدل اجازه میدهد تا ساختار واقعی نقص دادهها را یاد بگیرد و با آن سازگار شود، به جای اینکه بر فرضیات غیرواقعی درباره کامل بودن داده تکیه کند. این قابلیت به مدل توانایی میدهد که با چالشهای ذاتی جمعآوری داده در محیطهای غیرکنترلشده، مانند زندگی روزمره، به طور مؤثر مقابله کند.
* **مکانیسم ماسکگذاری ترکیبی**: مکانیسم ماسکگذاری تطبیقی و موروثی یک نوآوری کلیدی است که هم کارایی محاسباتی (از طریق حذف دراپاوت) و هم انعطافپذیری (از طریق ماسکگذاری توجه) را فراهم میکند. این ترکیب به مدل امکان میدهد تا با حجم بالای دادهها به طور مؤثر کار کند و در عین حال به تغییرات پویا در دسترسی به دادهها پاسخ دهد. این مکانیزم تضمین میکند که مدل میتواند درک جامعی از دادهها، چه موجود و چه از دست رفته، به دست آورد.
* **تعبیههای تعمیمپذیر (Generalizable Embeddings)**: یکی از نقاط قوت قابل توجه LSM-2، توانایی آن در تولید تعبیههای (embeddings) بسیار تعمیمپذیر است. حتی با استفاده از یک backbone ثابت (frozen backbone) و پروبهای خطی ساده، LSM-2 به نتایج هنری در هر دو وظایف سطح فردی/بالینی (مانند تشخیص بیماری) و سطح رویداد (مانند تشخیص فعالیت) دست مییابد و از پایههای نظارت شده و SSL متضاد پیشی میگیرد. این بدان معناست که بازنماییهای یادگرفته شده توسط مدل بسیار غنی و قابل انتقال هستند و میتوانند برای طیف گستردهای از کاربردها بدون نیاز به آموزش مجدد کامل مدل استفاده شوند، که این امر به طور چشمگیری کارایی و هزینه استفاده از مدل را کاهش میدهد.
* **قدرت تولیدی و تمایزدهنده**: LSM-2 تنها مدل ارزیابی شده در این حوزه است که قادر به هر دو کارکرد بازسازی سیگنالهای از دست رفته و همچنین تولید تعبیههای قابل استفاده در وظایف پاییندستی مختلف است. این قابلیت دوگانه نشاندهنده جامعیت مدل و پتانسیل آن برای کاربردهای گسترده در نظارت پزشکی و رفتاری در دنیای واقعی است. این مدل نه تنها میتواند به طور فعال دادههای از دست رفته را تکمیل کند، بلکه میتواند برای تشخیص الگوها و پیشبینی نتایج بالینی نیز به کار گرفته شود، که این امر آن را به ابزاری قدرتمند برای پژوهشگران و متخصصان سلامت تبدیل میکند.
نتیجهگیری
معرفی مدل LSM-2 با ماسکگذاری تطبیقی و موروثی (AIM) توسط محققان گوگل DeepMind، گامی بزرگ و حیاتی در جهت استقرار بینشهای مبتنی بر هوش مصنوعی با استفاده از دادههای حسگرهای پوشیدنی در دنیای واقعی است. این رویکرد نوآورانه، به طور مستقیم به چالش دیرینه نقص دادهها در حسگرهای پوشیدنی میپردازد و راه حلی قوی و کارآمد برای آن ارائه میدهد.
با پذیرش مستقیم نقصهای فراگیر و ساختاریافته در دادهها، و با یکپارچهسازی هوشمندانه قابلیتهای تولیدی (بازسازی دادههای از دست رفته) و تمایزدهنده (انجام وظایف طبقهبندی و رگرسیون) تحت یک مدل بنیادی کارآمد و قوی، LSM-2 زیربنای حیاتی را برای آینده هوش مصنوعی پوشیدنی و سلامت در محیطهای دادهای واقعی و ناقص فراهم میکند. این مدل نه تنها عملکردی برتر در تحلیل دادههای پیچیده و ناقص نشان میدهد، بلکه با قابلیت تعمیمپذیری و مقیاسپذیری خود، نویدبخش ارائه ابزارهایی دقیقتر و قابل اعتمادتر برای نظارت بر سلامت و مدیریت بیماریها است، حتی زمانی که دادهها به صورت کامل در دسترس نیستند. این پیشرفت، پتانسیل عظیمی برای تغییر شیوه مراقبتهای بهداشتی و درک بهتر از سلامت انسان دارد.
منبع: Google AI Blog: LSM-2 – Learning from Incomplete Wearable Sensor Data


