بهبود دقت مونتاژ ژنوم با DeepPolisher: تحولی در تحقیقات ژنومی
ژنوم، که در نوکلئوتیدها (یعنی بازهای A، T، G و C) رمزگذاری شده است، کلید درک وراثت، بیماریها و تکامل است. دستگاههای توالییابی DNA میتوانند این نوکلئوتیدها را بخوانند، اما انجام این کار با دقت بالا و در مقیاس وسیع، به دلیل اندازه بسیار کوچک جفت بازها، چالشبرانگیز است. با این حال، برای گشودن رازهای پنهان در ژنوم، باید بتوانیم یک ژنوم مرجع را تا حد امکان کامل و بدون نقص مونتاژ کنیم.
خطاهای موجود در مونتاژ میتوانند روشهای مورد استفاده برای شناسایی ژنها و پروتئینها را محدود کرده و باعث شوند فرآیندهای تشخیصی بعدی، واریانتهای ایجادکننده بیماری را از دست بدهند. در مونتاژ ژنوم، یک ژنوم چندین بار توالییابی میشود که امکان اصلاح خطاهای تکراری را فراهم میکند. با این حال، با توجه به اینکه ژنوم انسانی ۳ میلیارد نوکلئوتید دارد، حتی یک نرخ خطای کوچک میتواند به تعداد زیادی خطا منجر شود و کارایی ژنوم به دست آمده را محدود کند.
در راستای بهبود مستمر منابع برای مونتاژ ژنوم، ما DeepPolisher را معرفی میکنیم. DeepPolisher ابزاری متنباز است که بر پایه یادگیری عمیق توسعه یافته و به طور قابل توجهی دقت مونتاژ ژنوم را افزایش میدهد. این ابزار با همکاری موسسه ژنومیک دانشگاه کالیفرنیا سانتا کروز (UC Santa Cruz Genomics Institute) توسعه یافته است.
در مقاله اخیر ما با عنوان “Highly accurate assembly polishing with DeepPolisher” که در مجله Genome Research منتشر شده است، توضیح میدهیم که چگونه این ابزار، روشهای موجود را برای بهبود دقت مونتاژ ژنوم گسترش میدهد. DeepPolisher تعداد خطاها در مونتاژ را تا ۵۰ درصد و تعداد خطاهای درج یا حذف (“indel”) را تا ۷۰ درصد کاهش میدهد. این امر به ویژه از آن جهت حائز اهمیت است که خطاهای indel میتوانند در شناسایی ژنها اختلال ایجاد کنند و مانع از دستیابی به اطلاعات کامل ژنومی شوند.
پیشزمینه: چالشهای توالییابی DNA
روشهای متعددی برای اندازهگیری DNA وجود دارد، اما اغلب آنها شامل ثبت فرآیند تکثیر DNA هستند. یکی از این روشها، شامل اتصال مولکولهای نشاندار با رنگهای مختلف به نوکلئوتیدهای سازنده جداگانه و مشاهده فرآیند افزودن هر یک به مولکول DNA در حال تکثیر است. ماشینآلات تکثیر DNA همیشه رشته را در یک جهت خاص کپی میکنند، بنابراین اگرچه اطلاعات به طور افزونه در هر دو رشته رمزگذاری شدهاند، اما در هر زمان فقط نوکلئوتیدهای یک رشته خوانده میشوند. شناسایی دقیق نوکلئوتیدها نیازمند آشکارسازهایی است که قادر به تفکیک مولکولهای منفرد باشند، که این امر دقت اندازهگیریها را محدود میکند.
یکی از فناوریهای پیشگامانه برای مقیاسبندی این روش، که توسط Illumina توسعه یافته است، یک مولکول DNA مورد توالییابی را به خوشهای از کپیهای یکسان تبدیل میکند. سپس، این فرآیند را در حالی که خوشه به طور همزمان کپی میشود، نظارت میکند و بدین ترتیب سیگنال برای هر باز افزایش مییابد. با این حال، از آنجا که اطمینان از تکثیر کاملاً همزمان خوشه غیرممکن است، ممکن است خوشه از حالت همزمانی خارج شود و سیگنال بازهای مختلف با هم مخلوط شوند، که این امر طول DNA اندازهگیری شده با این روش را به چند صد نوکلئوتید محدود میکند. این توالیهای کوتاه، که “reads” نامیده میشوند، با وجود محدودیت طولی، همچنان برای تجزیه و تحلیل مفید هستند.
با مقایسه این “reads” با یک ژنوم مرجع، یعنی نقشهای موجود از ژنوم گونهای که قرار است توالییابی شود، میتوان بسیاری از “reads” کوتاه را به آن مرجع نگاشت. این فرآیند به ساخت یک ژنوم کاملتر از فرد مورد نمونهبرداری کمک میکند. سپس میتوان این ژنوم را با مرجع مقایسه کرد تا تنوعات ژنومی فرد را بهتر درک کرد.

ژنوم انسان از دو رشته تشکیل شده است که اطلاعات را به صورت افزونه رمزگذاری میکنند (سمت چپ)، که در کروموزومها سازماندهی شدهاند، و یک کپی کامل از هر والد به ارث میرسد (سمت راست). (تصاویر از NHGRI)
حتی با پیشرفت فناوری توالییابی، همچنان چندین چالش باقی مانده است. اولاً، این روش به وجود یک ژنوم مرجع قوی متکی است، که خود ایجاد آن فوقالعاده دشوار است. حتی با چنین مرجعی، برخی از قسمتهای ژنوم بیشتر شبیه قسمتهای دیگر هستند، که نگاشت مطمئن آنها به مرجع را دشوار میکند.
برای رفع این چالشها، دانشمندان فرآیندهایی را توسعه دادند که میتوانند مولکولهای منفرد را توالییابی کنند، و امکان “reads” با طول دهها هزار نوکلئوتید را فراهم آورند. در ابتدا، این فرآیند دارای نرخ خطای غیرقابل قبولی (حدود ۱۰٪) بود. این مشکل زمانی حل شد که Pacific Biosciences راهی برای توالییابی چندین بار یک مولکول مشابه پیدا کرد و نرخ خطا را به تنها ۱٪ کاهش داد، که مشابه روشهای “short-read” بود. گوگل و Pacific Biosciences با همکاری یکدیگر اولین نمایش این روش را بر روی ژنوم انسانی انجام دادند.
تیم ما سپس با توسعه DeepConsensus این فرآیند را فراتر برد. DeepConsensus از یک ترانسفورمر توالی برای ساخت دقیقتر توالی صحیح از بازهای اولیه دارای خطا استفاده میکند. امروزه Pacific Biosciences از DeepConsensus بر روی دستگاههای توالییابی “long-read” خود استفاده میکند تا نرخ خطا را به کمتر از ۰.۱٪ کاهش دهد. در حالی که این نرخ خطا به طور قابل توجهی بهتر از وضعیت قبلی است، دستیابی به دقت مورد نیاز برای ساخت یک ژنوم مرجع جدید و تقریباً کامل، نیازمند ترکیب “reads” توالی از چندین مولکول DNA از همان فرد است تا خطاهای باقیمانده بیشتر اصلاح شوند.
DeepPolisher: رویکردی نوین برای تصحیح خطاهای ژنومی
اینجاست که DeepPolisher وارد عمل میشود. DeepPolisher که از DeepConsensus اقتباس شده است، از معماری ترانسفورمر استفاده میکند که بر روی ژنوم یک رده سلولی انسانی اهدا شده به پروژه ژنومهای شخصی (Personal Genomes Project) آموزش دیده است. این ژنوم مرجع به طور جامع توسط NIST و NHGRI توصیف و با استفاده از فناوریهای توالییابی متعددی توالییابی شده است. تخمین زده میشود که تقریباً ۱۰۰٪ کامل باشد و صحت آن به ۹۹.۹۹۹۹۹٪ برسد. این میزان دقت، به معنای وجود تنها حدود ۳۰۰ تا ۱۰۰۰ خطای کلی در سراسر ۶ میلیارد نوکلئوتید ژنوم است (دو کپی از ژنوم مرجع ۳ میلیارد نوکلئوتیدی که از هر والد به ارث رسیده است).
با انجام توالییابی PacBio و مونتاژ ژنوم، میتوانیم خطاهای باقیمانده را شناسایی کرده و سپس مدلهایی را برای یادگیری تصحیح آنها آموزش دهیم. برای آموزش، مدل بازهای توالییابی شده، کیفیت آنها و میزان منحصر به فرد بودن نگاشت آنها به یک بخش معین از مونتاژ مرجع را دریافت میکند. در طول آموزش، ما فقط از کروموزومهای ۱ تا ۱۹ استفاده میکنیم. کروموزومهای ۲۰ تا ۲۲ را برای ارزیابی کنار میگذاریم و از عملکرد روی کروموزومهای ۲۱ و ۲۲ برای انتخاب مدل استفاده میکنیم، و دقتها را با استفاده از کروموزوم ۲۰ گزارش میکنیم.
معماری DeepPolisher به گونهای طراحی شده است که بتواند با دادههای پیچیده توالییابی DNA کار کند و حتی کوچکترین خطاها را نیز تشخیص دهد. این توانایی، به دلیل استفاده از شبکههای عصبی عمیق، به ویژه معماری ترانسفورمر که در پردازش زبان طبیعی نیز موفقیتآمیز بوده است، حاصل میشود. این مدل قادر است الگوهای ظریفی را در دادههای توالییابی شناسایی کند که نشاندهنده خطاهای احتمالی هستند و سپس تصحیحات لازم را پیشنهاد دهد.
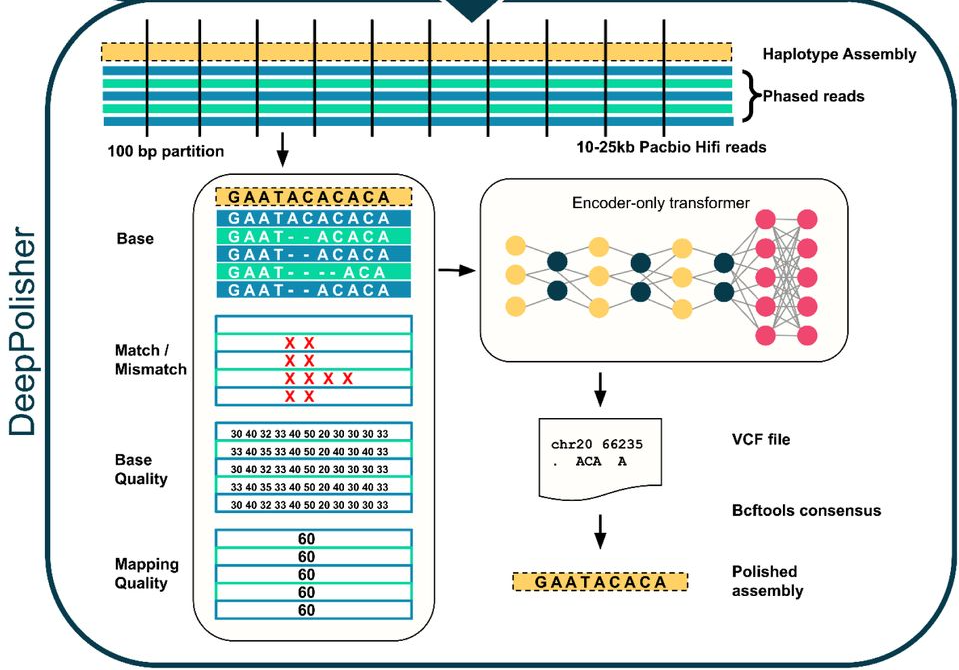
معماری DeepPolisher. “reads”های توالییابی شده بر اساس منشأ والدینی (“phasing”) دستهبندی شده و با مونتاژ اولیه ژنوم همتراز میشوند. کانالهای ورودی شامل اطلاعات بازها، کیفیت گزارش شده توسط توالییاب، کیفیت نگاشت (توانایی قرار دادن منحصر به فرد “reads” بر روی مونتاژ)، و توضیحات بازهای ناسازگار هستند. این اطلاعات به یک ترانسفورمر فقط-رمزگذار ارسال میشود که خطاها را در مونتاژ طبقهبندی کرده و سپس یک اصلاح را پیشنهاد میدهد که برای تصحیح مونتاژ استفاده میشود.
عملکرد DeepPolisher: افزایش بیسابقه دقت
DeepPolisher خطاها را در مونتاژ ژنوم تقریباً به نصف کاهش میدهد؛ این بهبود عمدتاً ناشی از کاهش خطاهای درج-حذف (“indel”) است که بیش از ۷۰ درصد کاهش مییابند. کاهش این نوع خطاها از اهمیت ویژهای برخوردار است، زیرا بازهای درج شده یا حذف شده میتوانند چارچوب خوانش یک ژن را تغییر دهند. این امر باعث میشود برنامههای حاشیهنویسی، آن ژن را هنگام برچسبگذاری ژنوم نادیده بگیرند و آن را از گزارشهای تحلیل بالینی یا کشف دارو پنهان کنند. بنابراین، دقت در شناسایی و حذف این خطاها برای استخراج اطلاعات ژنتیکی صحیح و کاربردی حیاتی است.
ما کیفیت یک ژنوم را با استفاده از “Q-score” (امتیاز Q) اندازهگیری میکنیم، که لگاریتم پایه ۱۰ احتمال خطا در یک موقعیت از ژنوم است. به عنوان مثال، امتیاز Q30 به معنای ۹۹.۹٪ احتمال صحیح بودن و امتیاز Q60 به معنای ۹۹.۹۹۹۹٪ احتمال صحیح بودن یک باز است. برای ارزیابی بهبود DeepPolisher، ما دادههای توالییابی را که برای مونتاژ ژنومهای جدید برای کنسرسیوم مرجع پانژنوم انسانی (HPRC) استفاده میشدند، جمعآوری کردیم. ما به دنبال خطاهای احتمالی در مونتاژ بودیم و تلاش کردیم ترکیباتی از نوکلئوتیدها را در مونتاژ شناسایی کنیم که در توالییابیهای دیگر از همان نمونه با فناوریهای توالییابی متفاوت وجود نداشتند.
با انجام این تحلیل در بخشهایی از ژنوم که روش توالییابی دیگر هیچ سوگیری سیستمی (منطقه مطمئن) نداشت، توانستیم بهبود مونتاژ را به طور متوسط از Q66.7 به Q70.1 نشان دهیم. این بهبود نشاندهنده افزایش قابل توجهی در دقت ژنومهای مونتاژ شده است. نکته مهم این است که ما بهبود را در هر یک از نمونههای ارزیابی شده نیز مشاهده کردیم، که نشاندهنده پایداری و قدرت DeepPolisher در کاربردهای عملی است. این نتایج، تأثیر مثبت DeepPolisher را در ایجاد ژنومهای با کیفیت بسیار بالا تأیید میکند.
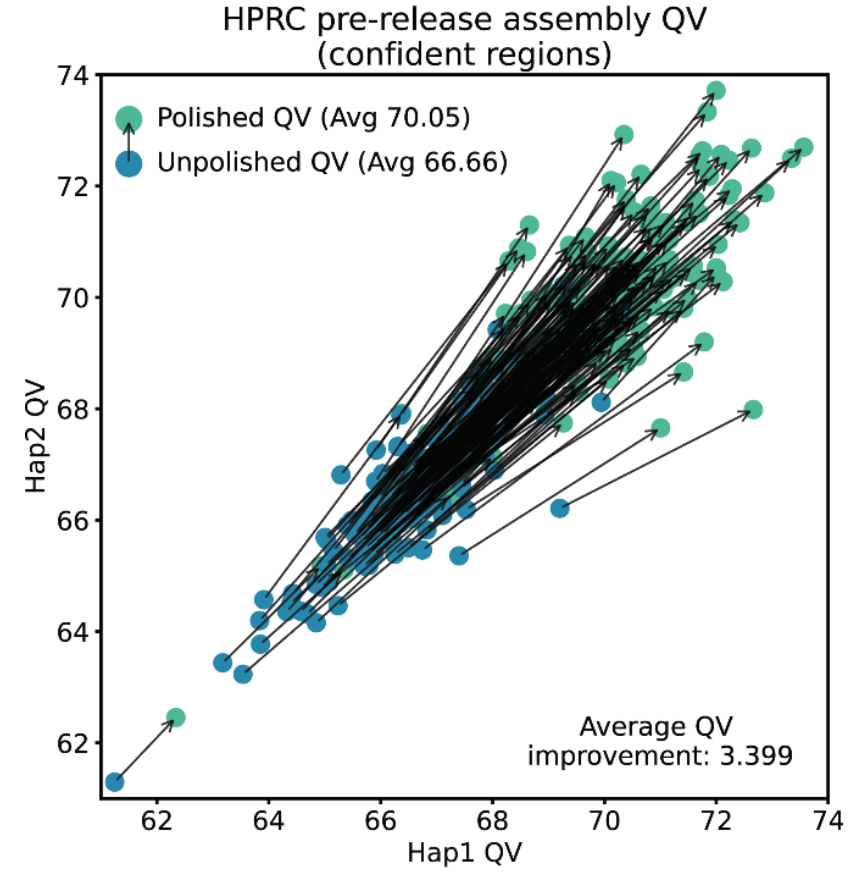
کیفیتهای مونتاژ قبل و بعد از DeepPolisher برای ۱۸۰ نمونه. برای هر نمونه، ژنوم بر اساس منشأ والدینی (کپی ژنوم منتقل شده از پدر یا مادر) که به عنوان “هاپلوتایپ” (Hap) ۱ یا ۲ نشان داده شده است، جدا میشود و کیفیت ارزیابی شده آن هاپلوتایپها نمایش داده میشود.
استقرار و کاربردهای DeepPolisher
DeepPolisher در حال حاضر برای بهبود منابع ژنومیک در جامعه علمی مورد استفاده قرار گرفته است. در ماه مه، کنسرسیوم HPRC دومین انتشار دادههای خود را اعلام کرد که شامل مونتاژ ژنوم توالییابی شده برای ۲۳۲ فرد بود، که افزایشی پنج برابر نسبت به انتشار اول نشان میداد. دادههای موجود در انتشار دوم، یک مرحله پالایش اضافی با DeepPolisher را پشت سر گذاشتند که خطاهای تک نوکلئوتیدی و indel را دو برابر کاهش داد. این امر منجر به نرخ خطای فوقالعاده پایین، کمتر از یک خطای باز در هر نیم میلیون باز مونتاژ شده، شد. این پیشرفت، زمینهساز توسعه تحقیقات ژنومیک و پزشکی دقیقتر است.
با ارائه DeepPolisher به عنوان یک ابزار متنباز، هدف ما این است که روشها را به طور گسترده در اختیار جامعه قرار دهیم. این رویکرد به شفافیت و همکاری در تحقیقات علمی کمک میکند و امکان دسترسی آسانتر به ابزارهای پیشرفته را برای محققان فراهم میآورد. با همکاری با کنسرسیوم مرجع پانژنوم انسانی، ما به دانشمندان کمک میکنیم تا بیماریهای ژنتیکی را برای افراد با هر قومیت و نژادی با دقت بیشتری تشخیص دهند. این تلاشها در راستای ایجاد یک پایگاه داده ژنومی فراگیرتر و دقیقتر برای بهبود سلامت جهانی است.
توانایی DeepPolisher در کاهش چشمگیر خطاها، به ویژه خطاهای indel که تأثیر بسزایی بر تفسیر ژنها دارند، آن را به ابزاری حیاتی در زمینههای مختلف بیوانفورماتیک و پزشکی تبدیل کرده است. از تشخیص بیماریهای نادر تا توسعه داروهای جدید و شخصیسازی درمانها، داشتن ژنومهایی با دقت بالا یک ضرورت است. DeepPolisher این امکان را فراهم میآورد که دانشمندان با اطمینان بیشتری به دادههای ژنومی خود اعتماد کنند و پژوهشهای خود را بر پایههایی محکمتر بنا نهند.
سپاس و قدردانی
این پست وبلاگ سهم گوگل را در توسعه DeepPolisher برای بهبود کیفیت مونتاژ ژنوم نشان میدهد. ادغام DeepPolisher در بافت گستردهتر تولید مراجع پانژنوم با دقت بالا، شامل مشارکت تقریباً ۱۹۵ نویسنده از ۶۸ سازمان مختلف است. ما از گروههای تحقیقاتی موسسه ژنومیک UCSC (GI) تحت نظر پروفسور بندیکت پاتن و پروفسور کارن میگا برای کمک در تحلیل اولیه و جهتگیریهای توسعه DeepPolisher سپاسگزاریم. ما از میرا ماستوراس و مبین اصغری برای رهبری تحلیل اصلی و ادغام DeepPolisher در خط لوله تولید پانژنوم قدردانی میکنیم. ما از مشارکتکنندگان فنی گوگل: پی-چوان چانگ، دانیل ای. کارول، الکسی کولسنیکوف، لوکاس برمبرینک، و ماریا ناتستاد سپاسگزاریم. ما از لیزی دورفمن، دیل وبستر، و کاترین چو برای رهبری استراتژیک، و مونیک برویلت برای کمک در نگارش تشکر میکنیم.
منبع: Google Research Blog



