مقدمه
عوامل هوش مصنوعی تجسمیافته امروزه با چالشهای بزرگی در تفسیر دستورالعملهای پیچیده و عملکرد قاطعانه در محیطهای پویا روبرو هستند. این عوامل باید بتوانند نه تنها ورودیهای چندوجهی را درک کنند، بلکه برای اهداف بلندمدت نیز برنامهریزی کرده و با شرایط غیرقابل پیشبینی سازگار شوند. در گذشته، مدلهای VLA که مستقیماً ورودیهای بصری و زبانی را به اقدامات رباتیک تبدیل میکردند، اغلب در انجام وظایف پیچیده و نیازمند استدلال عمیق با محدودیتهایی مواجه میشدند. این محدودیتها شامل ناتوانی در برنامهریزی برای آینده دور و دشواری در تعمیمپذیری به سناریوهای جدید بود.
روشهای نوینتر تلاش کردهاند تا با ادغام استدلال “زنجیرهای از فکر” (CoT) یا بهینهسازی مبتنی بر یادگیری تقویتی، این نواقص را برطرف کنند. با این حال، این رویکردها نیز اغلب با چالشهایی نظیر مقیاسپذیری و پایهگذاری دقیق ورودیهای بصری در محیطهای واقعی مواجه بودهاند. این مسائل به ویژه در وظایف دستکاری رباتیک که دارای تنوع بصری بالا و افق زمانی طولانی هستند، خود را نشان میدهند، چرا که این وظایف نیازمند سطحی از استدلال و برنامهریزی هستند که روشهای موجود به دشواری میتوانند آن را ارائه دهند.
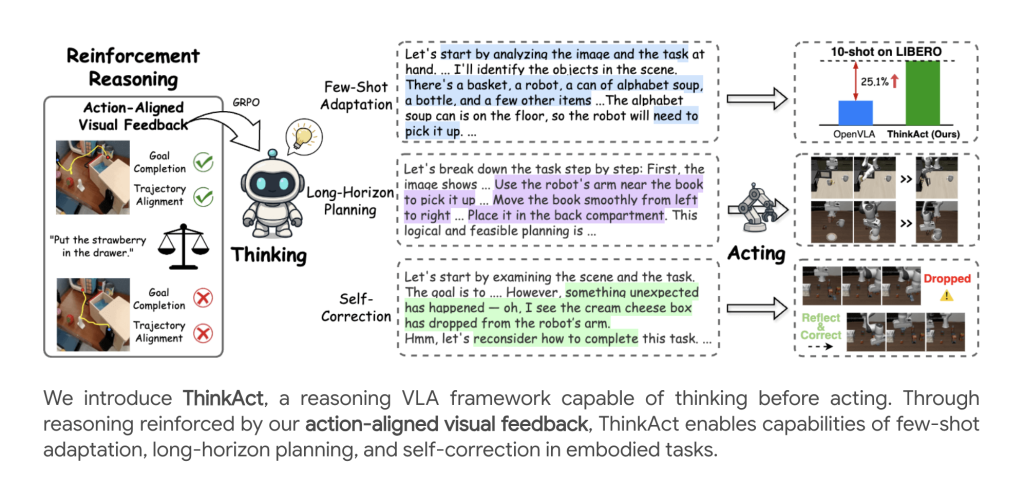
در پاسخ به این نیازها، ThinkAct توسط محققانی از NVIDIA و دانشگاه ملی تایوان معرفی شده است. این چارچوب پیشرفته، یک رویکرد نوآورانه برای استدلال دید-زبان-عمل (VLA) ارائه میدهد که با مفهوم “برنامهریزی نهفته بصری تقویتشده” (reinforced visual latent planning) تقویت شده است. ThinkAct به عوامل هوش مصنوعی این امکان را میدهد که قبل از انجام اقدامات فیزیکی، در یک فضای انتزاعی بصری “فکر” کنند و برنامهریزی دقیقی انجام دهند. این قابلیت برنامهریزی پیشازعمل، یک پل حیاتی بین استدلال چندوجهی سطح بالا و کنترل دقیق رباتیک سطح پایین ایجاد میکند و به طور چشمگیری قابلیتهای رباتها را در محیطهای پیچیده افزایش میدهد.

چارچوب ThinkAct
چارچوب ThinkAct با یک معماری دو سیستمی طراحی شده است که به طور تنگاتنگی با یکدیگر همکاری میکنند تا استدلال پیچیده و کنترل دقیق ربات را ممکن سازند. این طراحی ماژولار امکان میدهد تا هر جزء وظیفه خود را بهینه انجام دهد.
معماری دو سیستمی
ThinkAct از دو مؤلفه اصلی تشکیل شده است. اول، **مدل زبان بزرگ چندوجهی (MLLM) استدلالی** که مسئول استدلال گام به گام بر اساس صحنههای بصری و دستورالعملهای زبانی است. این مدل، یک “برنامه نهفته بصری” (visual plan latent) را تولید میکند که نیت سطح بالا و بافت برنامهریزی را کدگذاری میکند. دوم، **مدل عمل** که یک سیاست مبتنی بر ترانسفورمر است و توسط برنامه نهفته بصری شرطی میشود. این مدل وظیفه اجرای مسیر رمزگشاییشده را به عنوان اقدامات ربات در محیط بر عهده دارد.
این طراحی امکان **عملیات ناهمزمان** را فراهم میکند: MLLM “فکر میکند” و برنامهها را با سرعت کمتری تولید میکند، در حالی که ماژول عمل، کنترل دقیق را با فرکانس بالاتری انجام میدهد. این ناهمزمانی بسیار مهم است زیرا به مدل زبان بزرگ اجازه میدهد تا محاسبات سنگین استدلالی خود را بدون ایجاد تأخیر در اجرای اقدامات رباتیک انجام دهد.
برنامهریزی نهفته بصری تقویتشده
یک نوآوری اصلی در ThinkAct، رویکرد یادگیری تقویتی (RL) است که از **پاداشهای بصری همراستا با عمل** بهره میبرد. این سیستم پاداشدهی، نقش حیاتی در هدایت MLLM به سمت تولید برنامههایی دارد که نه تنها از نظر منطقی صحیح هستند، بلکه به طور فیزیکی نیز قابل اجرا توسط ربات میباشند. این پاداشها شامل دو بخش اصلی هستند: **پاداش هدف** که مدل را به همراستایی موقعیتهای شروع و پایان با مسیرهای نمایشی تشویق میکند، و **پاداش مسیر** که مسیر بصری پیشبینی شده را با استفاده از فاصله Dynamic Time Warping (DTW) به دقت با نمایشهای متخصص همخوانی میدهد. پاداش کلی `r` این پاداشهای بصری را با یک امتیاز صحت فرمت ترکیب میکند، که MLLM را به سمت تولید برنامههایی سوق میدهد که به اقدامات رباتیک قابل قبول فیزیکی تبدیل میشوند.
خط لوله آموزش
روش آموزش چند مرحلهای ThinkAct شامل فرآیندهای گام به گامی است. ابتدا، **بهینهسازی با نظارت (SFT)** با استفاده از دادههای حاشیهنویسی شده برای آموزش پیشبینی مسیر، استدلال و قالببندی پاسخها انجام میشود. سپس، **بهینهسازی تقویتی** (با GRPO) برای تشویق استدلال با کیفیت بالا با حداکثرسازی پاداشهای بصری همراستا با عمل اعمال میشود. در نهایت، **سازگاری عمل** با استفاده از یادگیری تقلید انجام میگیرد، که از خروجی برنامه نهفته مدل MLLM منجمد شده برای هدایت کنترل در محیطهای متنوع استفاده میکند.
استنتاج
در زمان استنتاج، با مشاهده یک صحنه و یک دستورالعمل زبانی، ماژول استدلال یک برنامه نهفته بصری تولید میکند. این برنامه نهفته سپس ماژول عمل را برای اجرای یک مسیر کامل شرطی میکند. این قابلیت، عملکرد قوی را حتی در محیطهای جدید و قبلاً دیدهنشده فراهم میسازد، که از این جهت ThinkAct را از بسیاری از مدلهای سنتی متمایز میکند.

نتایج تجربی
ThinkAct در مجموعهای از معیارهای دستکاری ربات و استدلال تجسمیافته، عملکردی فراتر از مدلهای پیشین از خود نشان داده است. این نتایج نه تنها بر کارایی و دقت چارچوب تأکید دارند، بلکه توانایی آن در تعمیمپذیری به وظایف و محیطهای جدید را نیز برجسته میسازند.
بنچمارکهای دستکاری ربات
آزمایشها در بنچمارکهای **SimplerEnv** و **LIBERO** برتری ThinkAct را به اثبات رساندهاند. در SimplerEnv، ThinkAct با ۱۱ تا ۱۷ درصد عملکرد بهتری نسبت به مدلهای پایه قوی نشان داده و در LIBERO نیز به بالاترین نرخ موفقیت کلی (۸۴.۴٪) دست یافته است. این عملکرد برتر در چالشهای مختلف، توانایی آن را در تعمیم و سازگاری با مهارتهای جدید و چیدمانهای ناشناخته تأیید میکند.

بنچمارکهای استدلال تجسمیافته
در بنچمارکهای **EgoPlan-Bench2**، **RoboVQA** و **OpenEQA**، ThinkAct دقت برنامهریزی چندمرحلهای و با افق زمانی طولانیمدت را به طور قابل توجهی افزایش داده است. همچنین، این مدل به نمرات BLEU و QA مبتنی بر LLM پیشرفتهای دست یافته که نشاندهنده درک معنایی بهبود یافته برای وظایف پاسخ به سؤالات بصری است.
سازگاری با تعداد داده کم (Few-Shot Adaptation)
ThinkAct توانایی **سازگاری مؤثر با تعداد داده کم** را دارد. حتی با تنها ۱۰ نمایش، این مدل دستاوردهای قابل توجهی در نرخ موفقیت نسبت به روشهای دیگر به دست آورده است، که قدرت برنامهریزی هدایتشده با استدلال را برای یادگیری سریع مهارتها یا محیطهای جدید برجسته میکند.
خودبازتابی و تصحیح
فراتر از موفقیت در انجام وظایف، ThinkAct **رفتارهای نوظهوری** مانند **تشخیص خطا** (مثلاً افتادن اشیا) را نشان میدهد. این قابلیت برای پایداری سیستم در محیطهای پویا حیاتی است. همچنین، ThinkAct دارای قابلیت **بازبرنامهریزی خودکار** است؛ سیستم میتواند به طور خودکار برنامههای خود را بازنگری کند تا از خطاها بازیابی شده و وظیفه را به پایان برساند. این توانایی، به لطف استدلال بر اساس توالی ورودیهای بصری اخیر حاصل میشود و انعطافپذیری ThinkAct را در برابر اختلالات غیرمنتظره به شدت افزایش میدهد.
مطالعات ابلیشن و تحلیل مدل
مطالعات ابلیشن بینشهای ارزشمندی را در مورد اجزای حیاتی ThinkAct ارائه میدهند. هر دو پاداش **هدف** و **مسیر** برای برنامهریزی ساختاریافته و تعمیمپذیری ضروری هستند؛ حذف هر یک از آنها عملکرد را به طور قابل توجهی کاهش میدهد. همچنین، اتکا تنها به پاداشهای سبک پرسش و پاسخ، قابلیت استدلال چندمرحلهای را محدود میکند. ThinkAct تعادلی بین استدلال (کند) و عمل (سریع) برقرار میکند و عملکرد قوی را بدون نیاز به محاسبات بیش از حد ممکن میسازد. این رویکرد به مدلهای MLLM کوچکتر نیز تعمیم مییابد و تواناییهای قوی را حفظ میکند.
جزئیات پیادهسازی
ستون فقرات اصلی ThinkAct، **Qwen2.5-VL 7B MLLM** است. مجموعهدادههای مورد استفاده برای آموزش شامل ویدئوهای متنوعی از نمایشهای ربات و انسان (مانند Open X-Embodiment و Something-Something V2) به علاوه مجموعهدادههای پرسش و پاسخ چندوجهی (مانند RoboVQA، EgoPlan-Bench و غیره) است. ThinkAct از یک رمزگذار بینایی (DINOv2)، یک رمزگذار متن (CLIP) و یک Q-Former برای اتصال خروجی استدلال به ورودی سیاست عمل استفاده میکند. آزمایشهای گسترده در محیطهای واقعی و شبیهسازی شده، مقیاسپذیری و پایداری این چارچوب را تأیید میکنند.
نتیجهگیری
ThinkAct از NVIDIA، استاندارد جدیدی را برای **عوامل هوش مصنوعی تجسمیافته** تعیین میکند. این چارچوب ثابت میکند که **برنامهریزی نهفته بصری تقویتشده**—جایی که عوامل “قبل از اقدام فکر میکنند”—عملکردی قوی، مقیاسپذیر و تطبیقپذیر را در وظایف پیچیده استدلال و دستکاری ربات در دنیای واقعی ارائه میدهد. طراحی دو سیستمی آن، شکلدهی پاداش و نتایج تجربی قوی، راه را برای رباتهای هوشمند و عمومی باز میکند که قادر به برنامهریزی با افق زمانی طولانی، سازگاری با تعداد داده کم و خودتصحیحی در محیطهای متنوع هستند.
**منبع:** Paper & Project


