
مقدمهای بر ژنوم و چالشهای توالییابی
کلید درک وراثت، بیماریها و تکامل در ژنوم نهفته است، که در نوکلئوتیدها (یعنی بازهای A، T، G و C) کدگذاری شده است. توالییابهای DNA قادر به خواندن این نوکلئوتیدها هستند، اما انجام این کار با دقت و در مقیاس وسیع، به دلیل مقیاس بسیار کوچک جفتبازها، چالشبرانگیز است. با این حال، برای گشودن رازهای نهفته در ژنوم، باید بتوانیم یک ژنوم مرجع را تا حد ممکن بینقص و نزدیک به واقعیت مونتاژ کنیم.
خطاها در مونتاژ میتوانند روشهای مورد استفاده برای شناسایی ژنها و پروتئینها را محدود کنند و میتوانند باعث شوند که فرآیندهای تشخیصی بعدی، واریانتهای مسبب بیماری را از دست بدهند. در مونتاژ ژنوم، یک ژنوم بارها توالییابی میشود که امکان تصحیح تکراری خطاها را فراهم میکند. با این حال، با توجه به اینکه ژنوم انسان 3 میلیارد نوکلئوتید است، حتی یک نرخ خطای کوچک نیز میتواند به تعداد زیادی خطا منجر شود و کاربرد ژنوم مشتق شده را محدود کند.
ضرورت دقت بالا در مونتاژ ژنوم، ناشی از تأثیرات عمیقی است که حتی کوچکترین خطاها میتوانند بر فهم ما از عملکرد بیولوژیکی و پاتولوژی بیماریها داشته باشند. یک خطای جزئی، مانند از دست دادن یا اضافه شدن یک نوکلئوتید، میتواند منجر به تغییر “قاب خوانش” ژن شود و در نتیجه پروتئین کاملاً متفاوتی تولید گردد یا اصلاً پروتئینی تولید نشود. این امر میتواند تشخیص دقیق بیماریهای ژنتیکی را مختل کرده و روند کشف داروهای جدید را با چالش مواجه سازد. بنابراین، دستیابی به یک ژنوم مرجع با دقت بالا، نه تنها یک هدف علمی است، بلکه یک ضرورت برای پیشرفتهای پزشکی و بیوتکنولوژیکی محسوب میشود.
با توجه به پیچیدگی و وسعت ژنوم انسان، فرآیند توالییابی و مونتاژ آن نیازمند رویکردهای نوآورانه و قدرتمند است. هرگونه عدم دقت در این مرحله اولیه میتواند منجر به نتایج گمراهکننده در مراحل بعدی تحلیل دادههای ژنومی شود. این امر بر اهمیت ابزارهایی مانند DeepPolisher تأکید میکند که با هدف رفع این نواقص و ارائه یک پایه دادهای قابل اعتمادتر برای تحقیقات ژنومی طراحی شدهاند. هدف نهایی، دستیابی به یک نقشه ژنتیکی است که به طور کامل و بدون خطا، تمامی اطلاعات ژنتیکی یک فرد را بازتاب دهد.
پیشزمینهای بر فناوریهای توالییابی DNA
در حالی که روشهای مختلفی برای اندازهگیری DNA وجود دارد، بیشتر آنها معمولاً شامل ثبت فرآیند کپیبرداری از DNA هستند. یک روش برای این کار شامل اتصال مولکولهای نشاندار با رنگهای مختلف به نوکلئوتیدهای سازنده جداگانه و مشاهده فرآیند اضافه شدن هر یک به مولکول DNA در حال کپیبرداری است. ماشینآلات کپیبرداری DNA همیشه رشته را در یک جهت خاص کپی میکنند، بنابراین اگرچه اطلاعات به صورت اضافی بر روی هر دو رشته کدگذاری شدهاند، اما در هر زمان فقط نوکلئوتیدهای یک رشته خوانده میشوند. شناسایی نوکلئوتیدها نیازمند آشکارسازهایی است که قادر به تفکیک مولکولهای منفرد باشند، که دقت اندازهگیریها را محدود میکند.
یکی از فناوریهای پیشگامانه برای مقیاسبندی این روش، که توسط Illumina توسعه یافته است، یک مولکول از DNA مورد توالییابی را به خوشهای از نسخههای یکسان کپی میکند. سپس فرآیند کپیبرداری همزمان خوشه را نظارت میکند، بدین ترتیب سیگنال برای هر باز افزایش مییابد. با این حال، از آنجا که نمیتوان اطمینان حاصل کرد که خوشه در هماهنگی کامل کپی میکند، ممکن است خوشه همگامسازی خود را از دست بدهد به طوری که سیگنال بازهای مختلف با هم ترکیب شوند، که طول DNA اندازهگیری شده با این روش را به چند صد نوکلئوتید محدود میکند.
اگرچه این توالیها (که “خوانش” نامیده میشوند) کوتاه هستند، اما همچنان برای تحلیل مفیدند. با مقایسه آنها با یک ژنوم مرجع، یعنی یک نقشه موجود از ژنوم گونه مورد توالییابی، امکان نقشهبرداری بسیاری از خوانشهای کوتاه به آن مرجع وجود دارد و بدین ترتیب ژنوم کاملتری از فرد نمونهبرداری شده ساخته میشود. این سپس میتواند با مرجع مقایسه شود تا بهتر درک شود که چگونه ژنوم فرد مورد نظر تغییر میکند. این روشها، با وجود محدودیتهایشان در طول خوانش، سنگ بنای اولیه ژنومیک مدرن را تشکیل دادند و امکان مطالعه گستردهتر تنوع ژنتیکی را فراهم آوردند.

ژنوم انسان از دو رشته تشکیل شده است که اطلاعات را به صورت اضافی کدگذاری میکنند (چپ)، و در کروموزومها سازماندهی شدهاند، با یک نسخه کامل که از هر والد به ارث رسیده است (راست). (تصاویر از NHGRI)
تکامل توالییابی: از PacBio تا DeepConsensus
حتی با فناوری توالییابی بهبود یافته، هنوز چندین چالش وجود دارد. اول، این روش به داشتن یک ژنوم مرجع قوی متکی است که خود ایجاد آن فوقالعاده دشوار است. حتی با چنین مرجعی، برخی از بخشهای ژنوم بیشتر شبیه بخشهای دیگر هستند که نقشهبرداری مطمئن آنها به مرجع را دشوار میکند.
برای مقابله با این چالشها، دانشمندان فرآیندهایی را توسعه دادند که میتوانستند مولکولهای منفرد را توالییابی کنند و خوانشهایی به طول دهها هزار نوکلئوتید را امکانپذیر سازند. در ابتدا، این فرآیند نرخ خطای غیرقابل قبولی (~10%) داشت. این مشکل زمانی برطرف شد که Pacific Biosciences راهی برای توالییابی یک مولکول مشابه در چندین مرحله توسعه داد و نرخ خطا را به تنها 1% کاهش داد، مشابه روشهای خوانش کوتاه. گوگل و Pacific Biosciences با یکدیگر در اولین نمایش این روش بر روی ژنوم انسان همکاری کردند. این پیشرفت، نقطه عطفی در توانایی ما برای خواندن بخشهای طولانیتر DNA با دقتی قابل قبول بود.
تیم ما سپس این موضوع را با توسعه DeepConsensus، که از یک ترنسفورمر توالی برای ساخت دقیقتر توالی صحیح از بازهای اولیه مستعد خطا استفاده میکند، فراتر برد. امروزه Pacific Biosciences DeepConsensus را بر روی توالییابهای خوانش طولانی خود به کار میگیرد تا نرخ خطا را به کمتر از 0.1% کاهش دهد. اگرچه این نرخ خطا به طور قابل توجهی بهتر از وضعیت قبلی است، اما دستیابی به دقت مورد نیاز برای ساخت یک ژنوم مرجع جدید و تقریباً بینقص، نیازمند ترکیب خوانشهای توالی از چندین مولکول DNA از همان فرد برای تصحیح بیشتر خطاهای باقیمانده است. این ضرورت، اهمیت توسعه DeepPolisher را برجسته میسازد.
DeepConsensus با بهرهگیری از قدرت شبکههای عصبی عمیق، به ویژه معماری ترنسفورمر، توانست جهش قابل توجهی در دقت توالییابی ایجاد کند. این مدل با تحلیل الگوهای پیچیده در دادههای خوانش، میتواند با اطمینان بیشتری بین سیگنالهای واقعی و نویزهای ناشی از خطا تمایز قائل شود. این پیشرفت، زمینه را برای دستیابی به دقتهای بیسابقه در مونتاژ ژنوم فراهم آورد و به پژوهشگران اجازه داد تا به ساختارهای ژنومی پیچیدهتری دست یابند. با این حال، حتی با این سطح از دقت، برای کاربردهای بالینی و تحقیقاتی که نیاز به صحت تقریباً ۱۰۰% دارند، هنوز جای بهبود وجود داشت.
DeepPolisher: گام بعدی در دقت ژنوم
اینجاست که DeepPolisher وارد عمل میشود. DeepPolisher که از DeepConsensus اقتباس شده است، از معماری ترنسفورمر آموزشدیده بر روی ژنوم یک رده سلولی انسانی استفاده میکند که به Personal Genomes Project اهدا شده است. این ژنوم مرجع توسط NIST و NHGRI به طور کامل شناسایی و با استفاده از بسیاری از فناوریهای مختلف توالییابی شده است. تخمین زده میشود که تقریباً 100% کامل و با صحت 99.99999% باشد. این میزان تقریباً به 300 تا 1000 خطای کلی در 6 میلیارد نوکلئوتید ژنوم (دو نسخه از مرجع 3 میلیارد نوکلئوتیدی که از هر والد به ارث رسیده است) میرسد.
با انجام توالییابی PacBio و مونتاژ ژنوم، میتوانیم خطاهای باقیمانده را شناسایی کرده و سپس مدلها را آموزش دهیم تا یاد بگیرند آنها را تصحیح کنند. برای آموزش، مدل بازهای توالییابی شده، کیفیت آنها و میزان منحصر به فرد بودن نقشهبرداری آنها به یک بخش خاص از مونتاژ مرجع را دریافت میکند. در طول آموزش، ما فقط از کروموزومهای 1 تا 19 استفاده میکنیم. کروموزومهای 20 تا 22 را کنار میگذاریم و از عملکرد بر روی کروموزومهای 21 و 22 برای انتخاب مدل استفاده میکنیم و دقتها را با استفاده از کروموزوم 20 گزارش میدهیم.
DeepPolisher با استفاده از تواناییهای شبکه عصبی ترنسفورمر، که در پردازش زبان طبیعی نیز کارایی خود را اثبات کرده است، میتواند روابط پیچیده بین خوانشهای توالی و خطاهای احتمالی را درک کند. این ابزار نه تنها به شناسایی خطاهای ساده، بلکه به درک الگوهای خطای خاص مرتبط با تکنیکهای توالییابی مختلف میپردازد. این درک عمیق، به DeepPolisher اجازه میدهد تا تصحیحاتی را انجام دهد که فراتر از منطق ساده تطابق توالی است و به پیچیدگیهای بیولوژیکی و فنی دادههای ژنومی توجه میکند.
فرآیند آموزش DeepPolisher شامل نمایش حجم عظیمی از دادههای ژنومی است که به دقت حاشیهنویسی شدهاند. این دادهها به مدل کمک میکنند تا با یادگیری از نمونههای صحیح و نادرست، توانایی خود را در تشخیص و اصلاح خطاهای واقعی بهبود بخشد. از آنجایی که ژنوم انسان دارای مناطق تکراری و پیچیدهای است که مونتاژ آنها دشوار است، DeepPolisher با تمرکز بر این چالشها، راهحلهای هوشمندانهای برای بهبود دقت در این نواحی ارائه میدهد. این ویژگی آن را به ابزاری بیبدیل در حوزه ژنومیک تبدیل کرده است.
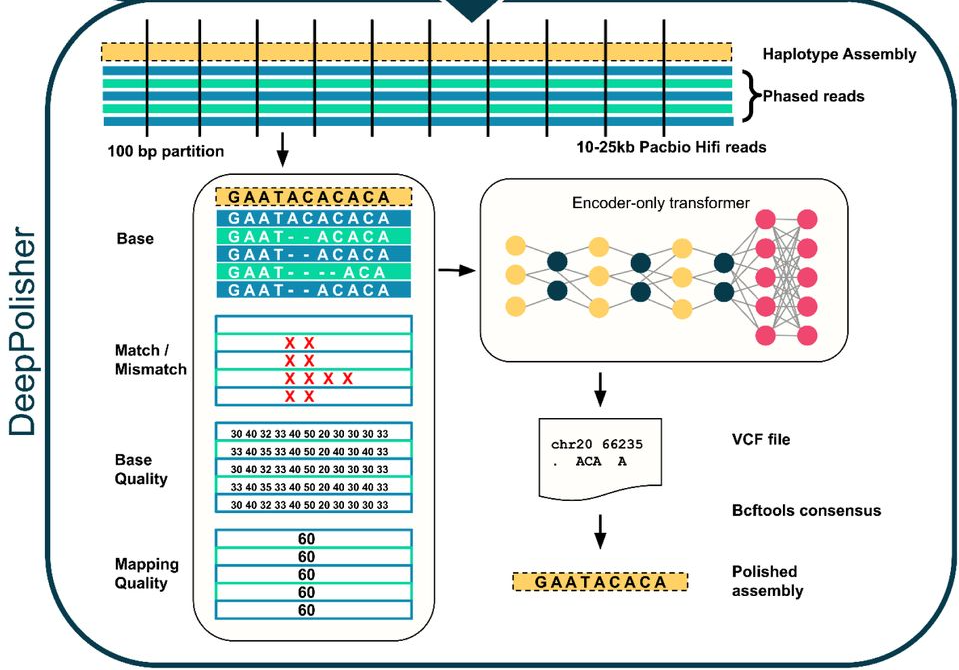
معماری DeepPolisher. دادههای توالییابی بر اساس منشأ والدینی (فازبندی) طبقهبندی شده و با مونتاژ اولیه ژنوم همتراز میشوند. کانالهای ورودی شامل: اطلاعات باز، کیفیت گزارششده توسط توالییاب، کیفیت نقشهبرداری (توانایی قرار دادن منحصر به فرد توالیها در مونتاژ)، و حاشیهنویسیهای بازهای نامطابق است. این اطلاعات به یک ترنسفورمر فقط-کدگذار (encoder-only Transformer) ارسال میشود که خطاهای موجود در مونتاژ را طبقهبندی کرده و سپس یک راه حل برای اصلاح پیشنهاد میکند که برای تصحیح مونتاژ استفاده میشود.
کارایی بینظیر DeepPolisher
DeepPolisher خطاها را در مونتاژ ژنوم تقریباً به نصف کاهش میدهد، بهبود قابل توجهی که عمدتاً ناشی از کاهش خطاهای حذف-اضافه (“indel”) است، که بیش از 70 درصد کاهش مییابند. کاهش این نوع خطاها از اهمیت ویژهای برخوردار است، زیرا بازهای اضافه شده یا حذف شده میتوانند قاب خوانش یک ژن را تغییر دهند و باعث شوند برنامههای حاشیهنویسی آن ژن را هنگام برچسبگذاری ژنوم نادیده بگیرند و آن را از گزارشها در تجزیه و تحلیل بالینی یا کشف دارو پنهان کنند.
کیفیت یک ژنوم را با استفاده از “امتیاز Q” اندازهگیری میکنیم، که لگاریتم مبنای 10 احتمال وجود خطا در یک موقعیت از ژنوم است. امتیاز Q30 به معنای 99.9% شانس صحیح بودن، در حالی که Q60 به معنای 99.9999% شانس صحیح بودن یک باز است. برای ارزیابی بهبود DeepPolisher، دادههای توالییابی مورد استفاده برای مونتاژ ژنومهای جدید برای کنسرسیوم مرجع پانژنوم انسانی (HPRC) را بررسی کردیم. ما به دنبال خطاهای احتمالی در مونتاژ با تلاش برای شناسایی ترکیباتی از نوکلئوتیدها در مونتاژ بودیم که در توالییابیهای دیگر از همان نمونه با فناوریهای توالییابی متفاوت رخ نمیدادند. با انجام این تحلیل در بخشهایی از ژنوم که روش توالییابی دیگر هیچ سوگیری سیستماتیکی ندارد (منطقه مطمئن)، میتوانیم بهبود مونتاژ را به طور متوسط از Q66.7 به Q70.1 نشان دهیم. همچنین بهبود در هر نمونه ارزیابی شده را نیز نشان میدهیم.
این سطح از بهبود در دقت، به ویژه در مورد خطاهای حذف-اضافه، تأثیرات عمیقی بر درک ما از عملکرد ژنها و پروتئینها دارد. با اطمینان بیشتر به صحت مونتاژ ژنوم، پژوهشگران میتوانند با دقت بیشتری به شناسایی ژنها، مناطق تنظیمی و واریانتهای مرتبط با بیماری بپردازند. این امر به نوبه خود، به توسعه روشهای تشخیصی دقیقتر و طراحی درمانهای هدفمندتر برای بیماریهای ژنتیکی کمک میکند. DeepPolisher نه تنها یک گام به جلو در دقت توالییابی است، بلکه یک ابزار قدرتمند برای تسریع درک ما از بیولوژی انسان و پیشرفت پزشکی محسوب میشود.
نتایج آزمایشگاهی به وضوح نشان میدهد که DeepPolisher نه تنها به صورت نظری بهبود ایجاد میکند، بلکه در عمل نیز عملکردی استثنایی دارد. این بهبود در تمامی نمونههای بررسی شده، قابلیت تعمیم و پایداری این ابزار را نشان میدهد. این بدان معناست که DeepPolisher میتواند به عنوان یک استاندارد جدید در فرآیند پولیشینگ ژنوم پذیرفته شود، که منجر به تولید دادههای ژنومی با کیفیت بالاتر در سراسر جامعه علمی میگردد. چنین پیشرفتهایی برای پروژههای بزرگ مقیاس مانند HPRC که هدفشان ساخت یک مرجع جامع از تنوع ژنتیکی انسان است، حیاتی است.
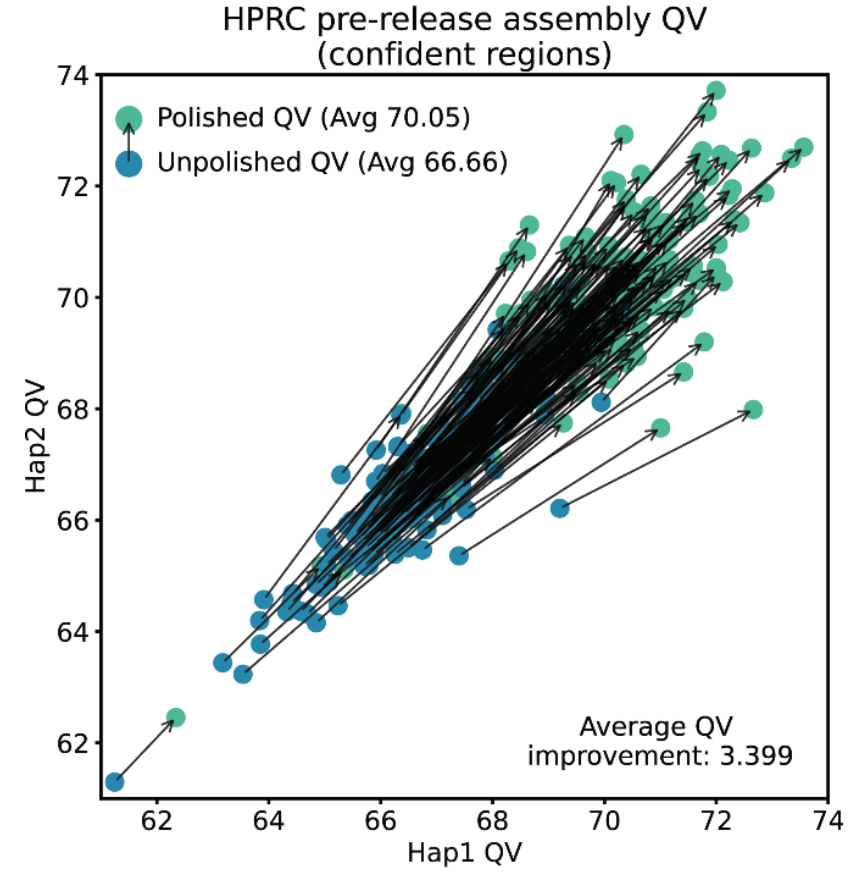
کیفیت مونتاژ قبل و بعد از صیقلدهی برای ۱۸۰ نمونه. برای هر نمونه، ژنوم بر اساس منشأ والدینی (نسخه ژنوم منتقل شده از پدر یا مادر) که به عنوان هاپلوتایپ (Hap) ۱ یا ۲ مشخص شده است، و کیفیت ارزیابی شده آن هاپلوتایپها، جدا میشود.
کاربرد و آینده DeepPolisher
DeepPolisher در حال حاضر برای بهبود منابع ژنومیک برای جامعه علمی مورد استفاده قرار گرفته است. در ماه می، HPRC دومین انتشار دادههای خود را اعلام کرد که شامل مونتاژهای ژنومی توالییابی شده بر روی 232 فرد بود، که افزایشی پنج برابری نسبت به اولین انتشار داشت. دادههای در انتشار دوم تحت یک مرحله پولیشینگ اضافی با DeepPolisher قرار گرفتند که خطاهای تک نوکلئوتیدی و حذف-اضافه را دو برابر کاهش داد و منجر به نرخ خطای بسیار پایینی کمتر از یک خطای باز در نیم میلیون باز مونتاژ شده گردید.
با ارائه DeepPolisher به عنوان یک ابزار متنباز، هدف ما این است که این روشها را به طور گسترده در اختیار جامعه قرار دهیم. با همکاری با کنسرسیوم مرجع پانژنوم انسانی، ما به دانشمندان کمک میکنیم تا بیماریهای ژنتیکی را برای افراد از تمامی نژادها با دقت بیشتری تشخیص دهند. این رویکرد متنباز، همکاریهای علمی را تشویق میکند و اطمینان میدهد که DeepPolisher به طور مداوم بهبود یابد و کاربردهای آن گسترش یابد. این ابزار، تواناییهای تشخیصی را به طور چشمگیری افزایش داده و به پزشکان و پژوهشگران امکان میدهد تا درک عمیقتری از پایههای ژنتیکی بیماریها به دست آورند.
علاوه بر این، دسترسی آزاد به DeepPolisher میتواند نوآوری را در توسعه ابزارهای بیوانفورماتیکی دیگر نیز تسریع بخشد. با وجود یک پایه قوی برای مونتاژ ژنوم، گروههای تحقیقاتی میتوانند منابع خود را بر روی چالشهای بعدی در تحلیل ژنومی متمرکز کنند، مانند شناسایی واریانتهای ساختاری پیچیده یا تحلیل بیان ژن. این چرخه بازخورد مثبت بین توسعه ابزار و تحقیق علمی، به پیشرفتهای سریعتر در حوزه ژنومیک منجر خواهد شد و به ما امکان میدهد تا به پتانسیل کامل اطلاعات ژنومی برای بهبود سلامت انسان دست یابیم.
به طور کلی، DeepPolisher نه تنها یک پیشرفت فنی مهم است، بلکه یک قدم کلیدی به سوی آیندهای است که در آن پزشکی شخصیسازی شده و درک عمیقتر از بیماریهای ژنتیکی برای همگان قابل دسترسی است. تعهد گوگل به ارائه ابزارهای متنباز، گواهی بر این رویکرد است که پیشرفت علمی باید مشارکتی و فراگیر باشد. این ابزار نه تنها کیفیت دادههای ژنومی را بهبود میبخشد، بلکه راه را برای اکتشافات علمی بیشمار و کاربردهای بالینی جدید هموار میسازد.
سپاسگزاریها
این پست وبلاگ سهم گوگل را در توسعه DeepPolisher برای بهبود کیفیت مونتاژهای ژنوم نشان میدهد. ادغام DeepPolisher در بستر گستردهتر تولید مراجع پانژنوم با دقت بالا شامل مشارکت نزدیک به 195 نویسنده از 68 سازمان مختلف است. ما از گروههای تحقیقاتی UCSC Genomics Institute (GI) تحت نظر پروفسور بندیکت پیتن و پروفسور کارن میگا برای کمک به تحلیل اولیه و جهتگیریهای توسعه DeepPolisher سپاسگزاریم. ما از میرا ماستوراس و موبین عصری برای رهبری تحلیل اصلی و ادغام DeepPolisher در خط لوله تولید پانژنوم قدردانی میکنیم. از مشارکتکنندگان فنی گوگل: پی-چوان چانگ، دانیل ای. کارول، الکسی کولسنیکوف، لوکاس برامبرینک، و ماریا ناتستاد سپاسگزاریم. از لیزی دورفمن، دیل وبستر، و کاترین چو برای رهبری استراتژیک، و از مونیک برولیته برای کمک در نگارش سپاسگزاریم.


