معرفی آینیاس: ابزاری نوآورانه برای سنگنوشتهنگاری لاتین
رشته سنگنوشتهنگاری، که بر مطالعه متون حکاکی شده بر مواد بادوام مانند سنگ و فلز تمرکز دارد، شواهد دست اول حیاتی برای درک دنیای روم ارائه میدهد. این حوزه با چالشهای متعددی از جمله کتیبههای تکهتکه، تاریخگذاری نامشخص، منشأ جغرافیایی متنوع، استفاده گسترده از اختصارات و مجموعه بزرگ و رو به رشد بیش از ۱۷۶,۰۰۰ کتیبه لاتین، که تقریباً ۱,۵۰۰ کتیبه جدید سالانه به آن اضافه میشود، روبرو است.
با وجود حجم عظیم اطلاعاتی که این کتیبهها در خود جای دادهاند، ماهیت آسیبدیده و پراکنده آنها بازیابی و تفسیر کامل را برای پژوهشگران دشوار میسازد. هر کتیبه، پنجرهای به گذشته است که میتواند اطلاعات ارزشمندی در مورد زندگی روزمره، قوانین، مذهب و ساختارهای اجتماعی روم باستان فاش کند، اما رمزگشایی آنها نیازمند دانش تخصصی و زمان بسیار زیادی است.
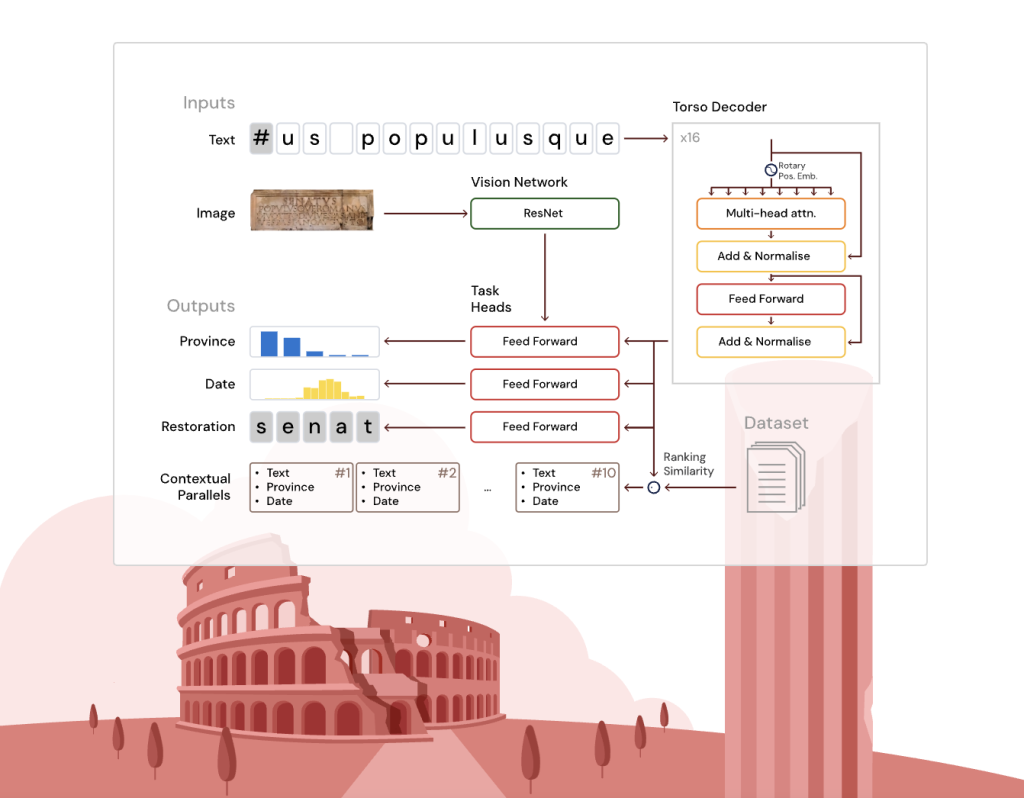
برای غلبه بر این موانع، گوگل دیپمایند (Google DeepMind) ابزاری انقلابی به نام آینیاس (Aeneas) را توسعه داده است. این یک شبکه عصبی مولد مبتنی بر معماری ترانسفورمر است که قادر به بازیابی بخشهای آسیبدیده متن، تاریخگذاری زمانی، انتساب جغرافیایی و زمینهسازی کتیبهها از طریق بازیابی نمونههای سنگنوشتهای مرتبط است. آینیاس با ترکیب قدرت هوش مصنوعی و تخصص انسانی، پتانسیل بالایی برای تحول در تحقیقات سنگنوشتهنگاری دارد.
چالشهای سنگنوشتهنگاری لاتین
کتیبههای لاتین بیش از دو هزاره، تقریباً از قرن هفتم پیش از میلاد تا قرن هشتم پس از میلاد، را در سراسر امپراتوری وسیع روم که شامل بیش از شصت استان بود، در بر میگیرند. این کتیبهها از فرمانهای امپراتوری و اسناد قانونی گرفته تا سنگقبرها و محرابهای نذری متفاوت هستند.
سنگنوشتهنگاران به طور سنتی متون جزئی از دست رفته یا ناخوانا را با استفاده از دانش دقیق زبان، فرمولها و زمینه فرهنگی بازیابی میکنند و کتیبهها را با مقایسه شواهد زبانی و مادی به زمانها و مکانهای خاصی نسبت میدهند. این فرآیند بسیار زمانبر و مستلزم تخصص عمیق در جزئیات تاریخی و زبانی است.
با این حال، بسیاری از کتیبهها به دلیل آسیب فیزیکی، دارای بخشهای گمشده با طولهای نامشخص هستند. پراکندگی جغرافیایی گسترده و تغییرات دیاکرونیک زبانی، تاریخگذاری و انتساب منشأ را پیچیده میکند، به خصوص زمانی که با اندازه عظیم مجموعه ترکیب میشود. شناسایی دستی نمونههای سنگنوشتهای مرتبط، کاری طاقتفرسا است و اغلب به دلیل تخصص محدود به مناطق یا دورههای خاص، محدود میشود.
این مسائل منجر به کندی پیشرفت در برخی جنبههای تحقیقاتی و دشواری در ایجاد ارتباطات گستردهتر بین کتیبههای مختلف شده است، زیرا حجم بالای دادهها مانع از تحلیل جامع توسط محققان انسانی میشود.

مجموعه داده سنگنوشتهنگاری لاتین (LED)
آینیاس بر روی مجموعه داده سنگنوشتهنگاری لاتین (LED) آموزش داده شده است، که یک مجموعه داده یکپارچه و هماهنگ از ۱۷۶,۸۶۱ کتیبه لاتین است که سوابق سه پایگاه داده اصلی را گردآوری کرده است. این مجموعه داده شامل تقریباً ۱۶ میلیون کاراکتر است که کتیبههایی از هفت قرن پیش از میلاد تا هشت قرن پس از میلاد را پوشش میدهد.
حدود ۵٪ از این کتیبهها دارای تصاویر خاکستری مرتبط هستند که امکان استفاده از اطلاعات بصری را در کنار دادههای متنی فراهم میآورد. این ترکیب دادههای متنی و تصویری، مدل را قادر میسازد تا درک جامعتری از کتیبهها داشته باشد.
مجموعه داده از رونویسیهای در سطح کاراکتر استفاده میکند که در آن از توکنهای ویژه جایگزین استفاده شده است: - برای متن از دست رفته با طول مشخص و # برای بخشهای گمشده با طول نامشخص. فرادادهها شامل منشأ در سطح استان در ۶۲ استان روم و تاریخگذاری بر اساس دهه است.
این رویکرد دقیق در سازماندهی و برچسبگذاری دادهها، پایه و اساس محکمی برای آموزش یک مدل هوش مصنوعی فراهم کرده است که میتواند با ظرافتهای پیچیده سنگنوشتهنگاری باستان کنار بیاید و نتایج دقیقی ارائه دهد.
معماری مدل و حالتهای ورودی
هسته آینیاس یک رمزگشای ترانسفورمر عمیق و باریک است که بر اساس معماری T5 ساخته شده و با جاسازیهای موقعیتی چرخشی برای پردازش مؤثر کاراکترهای محلی و متنی سازگار شده است. ورودی متنی در کنار تصاویر کتیبههای اختیاری (در صورت موجود بودن) از طریق یک شبکه کانولوشنی کمعمق (ResNet-8) پردازش میشود که جاسازیهای تصویری را فقط به سر انتساب جغرافیایی تغذیه میکند.
این طراحی ماژولار به آینیاس اجازه میدهد تا وظایف مختلف را با دقت بالا انجام دهد، در حالی که ورودیهای مختلف را به طور مؤثر ترکیب میکند. ترکیب دادههای متنی و تصویری به مدل کمک میکند تا زمینههایی را که فقط از یک نوع داده قابل استخراج نیستند، شناسایی کند.
این مدل شامل چندین سر وظیفه تخصصی برای انجام موارد زیر است:
- بازیابی: پیشبینی کاراکترهای از دست رفته، پشتیبانی از شکافهای ناشناخته با طول دلخواه با استفاده از یک طبقهبندی کننده عصبی کمکی.
- انتساب جغرافیایی: طبقهبندی کتیبهها در میان ۶۲ استان با ترکیب جاسازیهای متنی و بصری.
- انتساب زمانی: تخمین تاریخ متن بر اساس دهه با استفاده از یک توزیع احتمال پیشبینیکننده که با بازههای تاریخی همسو است.
علاوه بر این، مدل یک جاسازی یکپارچه غنی شده تاریخی را با ترکیب خروجیهای هسته و سرهای وظیفه تولید میکند. این جاسازی امکان بازیابی نمونههای سنگنوشتهای رتبهبندی شده را با استفاده از شباهت کسینوسی فراهم میکند، که آنالوژیهای زبانی، سنگنوشتهای و فرهنگی گستردهتری را فراتر از مطابقت دقیق متنی شامل میشود.
تنظیمات آموزش و افزایش داده
آموزش بر روی سختافزار TPU v5e با اندازههای دستهای تا ۱۰۲۴ جفت متن و تصویر انجام میشود. تلفات برای هر وظیفه با وزندهی بهینه ترکیب میشوند. دادهها با ماسکگذاری تصادفی متن (تا ۷۵٪ کاراکترها)، برش متن، حذف کلمات، حذف علائم نگارشی، افزایش تصویر (بزرگنمایی، چرخش، تنظیمات روشنایی/کنتراست)، دراپاوت (dropout) و هموارسازی برچسب (label smoothing) برای بهبود تعمیمپذیری افزایش مییابند.
این تکنیکهای افزایش داده برای اطمینان از اینکه مدل قادر به مقابله با انواع نویز و ناقص بودن دادهها در دنیای واقعی است، حیاتی هستند. با آموزش بر روی دادههای متنوعتر، آینیاس میتواند پیشبینیهای قویتری را برای کتیبههای آسیبدیده ارائه دهد.
پیشبینی از جستجوی بیم (beam search) با منطق غیرترتیبی تخصصی برای بازیابی متن با طول نامشخص استفاده میکند، که چندین کاندیدای بازیابی را بر اساس احتمال مشترک و طول رتبهبندی میکند. این قابلیت به محققان گزینههای متنوعی را برای بررسی میدهد و دقت نهایی را افزایش میدهد.
این فرآیند به مدل اجازه میدهد تا نه تنها دقیقترین پیشبینی را انجام دهد، بلکه همچنین احتمالات جایگزین را که ممکن است برای متخصصان انسانی ارزشمند باشد، ارائه دهد.
عملکرد و ارزیابی
آینیاس بر روی مجموعه آزمایشی LED و از طریق یک مطالعه همکاری انسان و هوش مصنوعی با ۲۳ سنگنوشتهنگار، ارزیابی شد و پیشرفتهای چشمگیری را نشان داد:
- بازیابی: نرخ خطای کاراکتر (CER) با پشتیبانی آینیاس به تقریباً ۲۱٪ کاهش یافت، در مقایسه با ۳۹٪ برای متخصصان انسانی بدون کمک. خود مدل به حدود ۲۳٪ CER در مجموعه آزمایشی دست یافت. این نشان دهنده پتانسیل هوش مصنوعی در افزایش چشمگیر دقت بازیابی متن است.
- انتساب جغرافیایی: در طبقهبندی صحیح استان در میان ۶۲ گزینه، به حدود ۷۲٪ دقت دست یافت. با کمک آینیاس، مورخان دقت را تا ۶۸٪ بهبود بخشیدند، که از هر یک به تنهایی عملکرد بهتری داشت.
- انتساب زمانی: میانگین خطا در تخمین تاریخ برای آینیاس تقریباً ۱۳ سال بود، در حالی که مورخان با کمک آینیاس خطا را از حدود ۳۱ سال به ۱۴ سال کاهش دادند. این دقت بالا در تاریخگذاری، تحلیلهای تاریخی را به طور قابل توجهی دقیقتر میکند.
- نمونههای مرتبط با زمینه: نمونههای سنگنوشتهای بازیابی شده در تقریباً ۹۰٪ موارد به عنوان نقاط شروع مفید برای تحقیقات تاریخی پذیرفته شدند و اعتماد مورخان را به طور متوسط ۴۴٪ افزایش دادند.
این بهبودها از نظر آماری معنیدار هستند و سودمندی مدل را به عنوان یک تقویتکننده برای دانش تخصصی نشان میدهند. آینیاس نه تنها دقت را افزایش میدهد بلکه زمان لازم برای تحقیقات را نیز به شدت کاهش میدهد، که این امر به محققان اجازه میدهد بر جنبههای تفسیری و عمیقتر کار خود تمرکز کنند.
کاربرد و آینده آینیاس
مطالعات موردی
Res Gestae Divi Augusti:
تحلیل آینیاس از این کتیبه یادبود، توزیعهای تاریخگذاری دووجهی را نشان میدهد که منعکسکننده بحثهای علمی درباره لایهها و مراحل ترکیبی آن (اواخر قرن اول پیش از میلاد و اوایل قرن اول پس از میلاد) است. نقشههای برجستگی، اشکال زبانی حساس به تاریخ، املای باستانی، عناوین نهادی و نامهای شخصی را برجسته میکنند، که دانش تخصصی سنگنوشتهنگاران را منعکس میکند.
نمونههای بازیابی شده عمدتاً شامل فرمانهای قانونی امپراتوری و متون رسمی سنا هستند که ویژگیهای فرمولی و ایدئولوژیکی مشترکی دارند. این توانایی آینیاس در یافتن ارتباطات عمیقتر، حتی در متون بسیار معروف، نشان از عمق تحلیل آن دارد.
محراب نذری از ماینتس (CIL XIII, 6665):
این کتیبه که در سال ۲۱۱ پس از میلاد توسط یک مقام نظامی وقف شده بود، به طور دقیق تاریخگذاری و به طور جغرافیایی به ژرمانیای علیا و استانهای مرتبط نسبت داده شد. نقشههای برجستگی فرمولهای کلیدی تاریخگذاری کنسولی و ارجاعات مذهبی را شناسایی کردند. آینیاس نمونههای بسیار مرتبطی را از جمله یک محراب مربوط به سال ۱۹۷ پس از میلاد را بازیابی کرد که فرمولهای متنی و نمادشناسی نادری را به اشتراک میگذاشت و ارتباطات تاریخی معنیداری را فراتر از همپوشانی مستقیم متن یا فرادادههای مکانی آشکار کرد.
این مورد نشان میدهد که آینیاس میتواند به محققان در کشف ارتباطات پنهان بین کتیبهها کمک کند، که ممکن است به دلیل پیچیدگی و حجم دادهها از دید انسانی پنهان بمانند.
ادغام در جریان کار پژوهشی و آموزش
آینیاس به عنوان یک ابزار همکار عمل میکند، نه جایگزینی برای مورخان. این ابزار جستجو برای نمونههای سنگنوشتهای، کمک به بازیابی و پالایش انتساب را سرعت میبخشد و به دانشمندان این امکان را میدهد که بر تفسیرهای سطح بالاتر تمرکز کنند. این همکاری بین هوش مصنوعی و انسان، کارایی و عمق تحقیقات را به طور همزمان افزایش میدهد.
ابزار و مجموعه داده از طریق پلتفرم Predicting the Past تحت مجوزهای آزاد در دسترس عموم قرار گرفتهاند. این دسترسی آزاد به دادهها و ابزارها، همکاریهای بیشتری را در جامعه پژوهشی تشویق میکند و به دموکراتیزه کردن دسترسی به ابزارهای پیشرفته هوش مصنوعی برای تحقیقات تاریخی کمک میکند.
یک برنامه درسی آموزشی نیز با همکاری با دانشآموزان دبیرستانی و مربیان توسعه یافته است که سواد دیجیتالی بین رشتهای را با پل زدن بین هوش مصنوعی و مطالعات کلاسیک ترویج میکند. این رویکرد به نسلهای آینده از محققان اجازه میدهد تا از سنین پایین با این ابزارهای قدرتمند آشنا شوند.
سوالات متداول ۱: آینیاس چیست و چه وظایفی را انجام میدهد؟
آینیاس یک شبکه عصبی مولد چندوجهی است که توسط گوگل دیپمایند برای سنگنوشتهنگاری لاتین توسعه یافته است. این ابزار به مورخان در بازیابی متن آسیبدیده یا از دست رفته در کتیبههای لاتین باستان، تخمین تاریخ آنها با خطای حدود ۱۳ سال، انتساب منشأ جغرافیایی آنها با دقت حدود ۷۲٪، و بازیابی کتیبههای موازی تاریخی مرتبط برای تحلیل متنی کمک میکند.
سوالات متداول ۲: آینیاس چگونه با کتیبههای ناقص یا آسیبدیده کنار میآید؟
آینیاس میتواند بخشهای متنی گمشده را حتی زمانی که طول شکاف ناشناخته است، پیشبینی کند، قابلیتی که به عنوان بازیابی طول-دلخواه شناخته میشود. این ابزار از یک معماری مبتنی بر ترانسفورمر و سرهای شبکه عصبی تخصصی برای تولید چندین فرضیه بازیابی محتمل، که بر اساس احتمال رتبهبندی شدهاند، استفاده میکند که ارزیابی متخصص و تحقیقات بیشتر را تسهیل میکند.
سوالات متداول ۳: آینیاس چگونه در جریان کار مورخان ادغام میشود؟
آینیاس لیستهای رتبهبندی شدهای از نمونههای سنگنوشتهای و فرضیههای پیشبینیکننده برای بازیابی، تاریخگذاری و منشأ را در اختیار مورخان قرار میدهد. این خروجیها اعتماد و دقت مورخان را افزایش میدهند، زمان تحقیق را با پیشنهاد سریع متون مرتبط کاهش میدهند، و از تحلیل مشترک انسان و هوش مصنوعی پشتیبانی میکنند. مدل و مجموعه دادهها به طور آزاد از طریق پلتفرم Predicting the Past قابل دسترسی هستند.
منبع مقاله: MarkTechPost



